Underwater Surface Defect Recognition of Bridges Based on Fusion of Semantic Segmentation and Three-Dimensional Point Cloud
Publication: Journal of Bridge Engineering
Volume 30, Issue 1
Abstract
This study introduces an innovative approach for identifying surface defects in underwater bridge structures through the fusion of deep learning and three-dimensional point cloud. The method employs a U2-Net neural network enhanced with residual U-blocks to effectively capture defect features across scales and merge multiscale underwater image attributes to produce significant probability images for defect detection. By leveraging three-dimensional digital image correlation techniques, the method reconstructs the bridge pier surfaces’ physical dimensions from point cloud, enabling precise defect contour and size recognition. The fusion of deep learning’s semantic segmentation with the accurate dimensions from point cloud significantly improves defect detection accuracy, achieving pixel accuracies of 0.943 and 0.811 for foreign objects and spalling and exposed rebars, respectively, and an Intersection over Union of 0.733 and 0.411. The method’s millimeter-level precision in point cloud reconstruction further allows for detailed defect dimensioning, enhancing both the accuracy and the quantitative measurement capabilities of underwater bridge inspections, and shows promise for future advanced applications in this field.
Introduction
Bridge engineering, as a fundamental project in the national economic construction of our country, occupies a crucial position in transportation and logistics, exerting an undeniable influence on the development of the national economy (Abdallah et al. 2022). Based on statistics (MOT 2024), by the end of 2023, the number of highway bridges in China exceeded 1 million, an increase of over 40,000 from the previous year. The underwater structures of bridge foundations and piers are subjected to harsher conditions compared to those above water (Chen et al. 2023). Traditional underwater structure inspection techniques can be classified into three categories: imaging methods, tactile methods, and magnetic film flaw detection methods. Traditional imaging methods involve professional divers operating underwater photography and videography equipment to capture defects (Sun et al. 2023). In situations where clear imaging is impossible, divers rely on tactile methods to estimate defects by touching structures based on their experience. Magnetic film flaw detection complements tactile methods. It creates underwater molds of defects, which are later quantitatively described on land (Song et al. 2023). Traditional underwater inspection methods, which depend on diver-obtained images, face limitations due to depth, flow velocity, water clarity, and diver skill, complicating the detailed analysis of surface defects.
In recent years, researchers have turned to deep learning to address the limitations of traditional manual methods in detecting and identifying defects in civil engineering structures (Li et al. 2023). Against this backdrop, deep learning techniques, particularly target detection and semantic segmentation (Minaee et al. 2021; Iizuka et al. 2017; Dekel et al. 2018), have emerged as key components in intelligent defect detection systems for structures (Ho et al. 2013; Liu et al. 2019). Cha et al. (2017) pioneered convolutional neural networks (CNNs) for concrete crack detection. Their five-layer CNN model effectively identified cracks and utilized sliding window detection for rough localization, showing superior accuracy over traditional edge detection methods. Li et al. (2019) proposed a multiscale deep bridge crack classify (DBCC) model, which improved accuracy and robustness through enhancements in the sliding window algorithm using image pyramids and regions of interest. Choi and Cha (2020) introduced a real-time segmentation network tailored for cracks, achieving a processing rate of 36 frames/s for images sized at 1,025 × 512 pixels, representing a 46-fold performance improvement over alternative models. Alipour et al. (2019) utilized a fully convolutional neural network (FCN) for pixel-level crack segmentation, achieving a recognition accuracy of 92% for crack pixels and validating FCN’s effectiveness in crack segmentation at the pixel level. Kim and Cho (2019) utilized mask R-CNN for identifying cracks ranging from 0.1 to 1.0 mm, achieving high-precision recognition for cracks above 0.3 mm. To enhance precision and robustness in identifying minor defects, Wang et al. (2018) introduced the crack FCN model, fusing fully convolutional networks into image crack detection. The approach involved enhancing resolution, deepening the network, and fusing higher-scale deconvolution layers for better local detail. Additionally, Zhu et al. (2020) integrated transfer learning with CNNs to achieve automatic extraction of bridge defect features, attaining an accuracy of 97.8%, which significantly surpasses traditional methods. Cardellicchio et al. (2023) employed multiple CNNs to identify bridge defects and used explainable artificial intelligence (AI) methods to analyze the results, enhancing their reliability. Despite numerous studies on defect recognition via deep learning, most of them focus on analyzing bridge superstructures and their surface defects through qualitative and quantitative means. However, underwater defect recognition remains unexplored, attributed to data collection challenges, data scarcity, and limited focus, indicating a need for further research in this domain.
Furthermore, the segmentation accuracy of defect recognition models based on deep learning has a significant impact on the measurement of underwater defect sizes, with some segmented regions prone to misrecognition. Optical measurement methods offer precise detection of defect pixel contours, facilitating more refined measurements of localized defects through three-dimensional (3D) point cloud reconstruction. Optical measurement methods include 3D digital image correlation (DIC), grid projection (surface structured light method), and line structured light method. Among these, the 3D DIC method stands out for its noncontact, nondestructive, full-field, and high-precision measurement advantages in structural three-dimensional shape and deformation measurement (Shao et al. 2016; Wu et al. 2023), widely applied in quality inspection and safety assessment of structures, devices, and products in fields such as aerospace, civil engineering, transportation, and mechanical engineering (Liu et al. 2016; Dong et al. 2019). The 3D DIC method was first proposed by Peters and Ranson (1982) and the Japanese scholar Yamaguchi (1981). This method processes images of the tested object’s surface before and after deformation using image processing techniques, and correlates the speckle regions to calculate the full-field three-dimensional shape, displacement, and strain of the tested object’s surface (Sutton et al. 2009). The development of the 3D DIC method has matured over time, with measurement accuracy reaching 0.02 pixels (Pan et al. 2009; Pan and Xie 2007). Compared to traditional three-dimensional laser scanners and structured light, 3D DIC is cost-effective and highly resistant to interference, making it suitable for high-precision measurements in complex scenarios. Zhang et al. (2016) conducted measurements of spherical shapes using 3D DIC and analyzed the measurement accuracy in detail. Gu et al. (2021) employed multicamera digital image correlation to measure the full-field strain of concrete beams and locate and measure the dimensions of surface cracks. Pan et al. (2021) successfully applied 3D DIC to measure underwater propeller deformation, further demonstrating the applicability of the method.
This paper proposes a method for identifying and quantifying surface defects in underwater bridge structures by combining deep learning and 3D point cloud. In a laboratory setting, images of surface defects and physical measurements were collected from the full-scale underwater bridge pier. The U2-Net model was used for defect identification and segmentation, and the 3D DIC point cloud measurement technique was employed to measure the physical dimensions of the defects. The pixel boundaries of the segmentation results were then corrected using elevation change data from the point cloud, filling in missing defect pixels within enclosed areas. Finally, the missing parts of the point cloud were filled based on corresponding adjacent values using the segmentation results. Experimental results demonstrate that the proposed method effectively identifies and measures surface defects in underwater structures with millimeter-level precision, facilitating its potential application in the quantitative detection of underwater bridge structure defects in the future.
Methodology
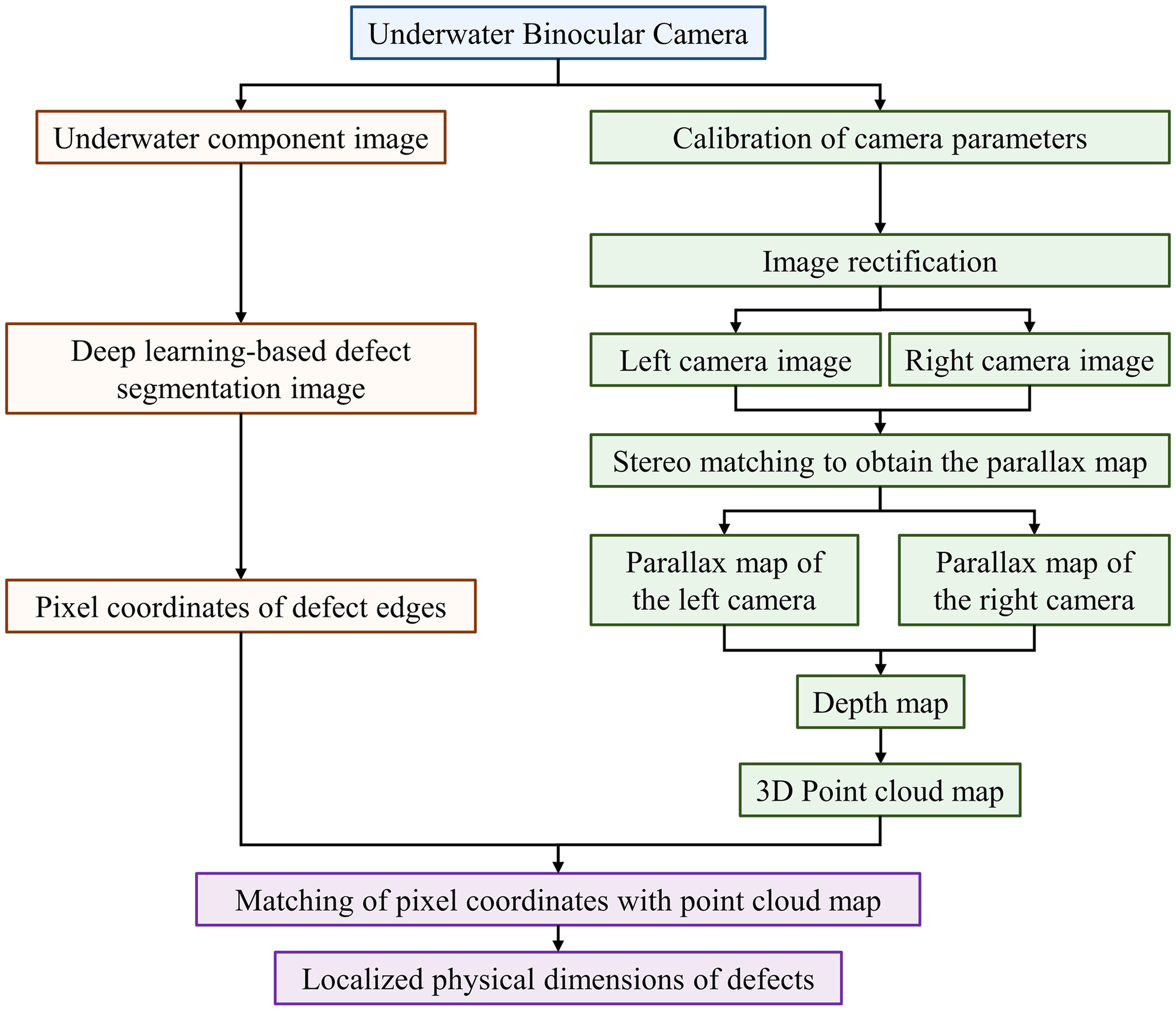
In this work, the innovative defect detection approach that fuses deep learning with 3D point cloud fusion is introduced, encompassing deep learning–based defect recognition, 3D DIC, and their synergistic fusion, as shown in Fig. 1. The methodology involves initially applying deep learning for defect feature extraction and segmentation in images, followed by employing 3D DIC for physical dimension calculations and stereo matching for point cloud generation. Subsequent matching of deep learning–segmented defect regions with point cloud data enables refined defect measurement through the complementary strengths of each technique.
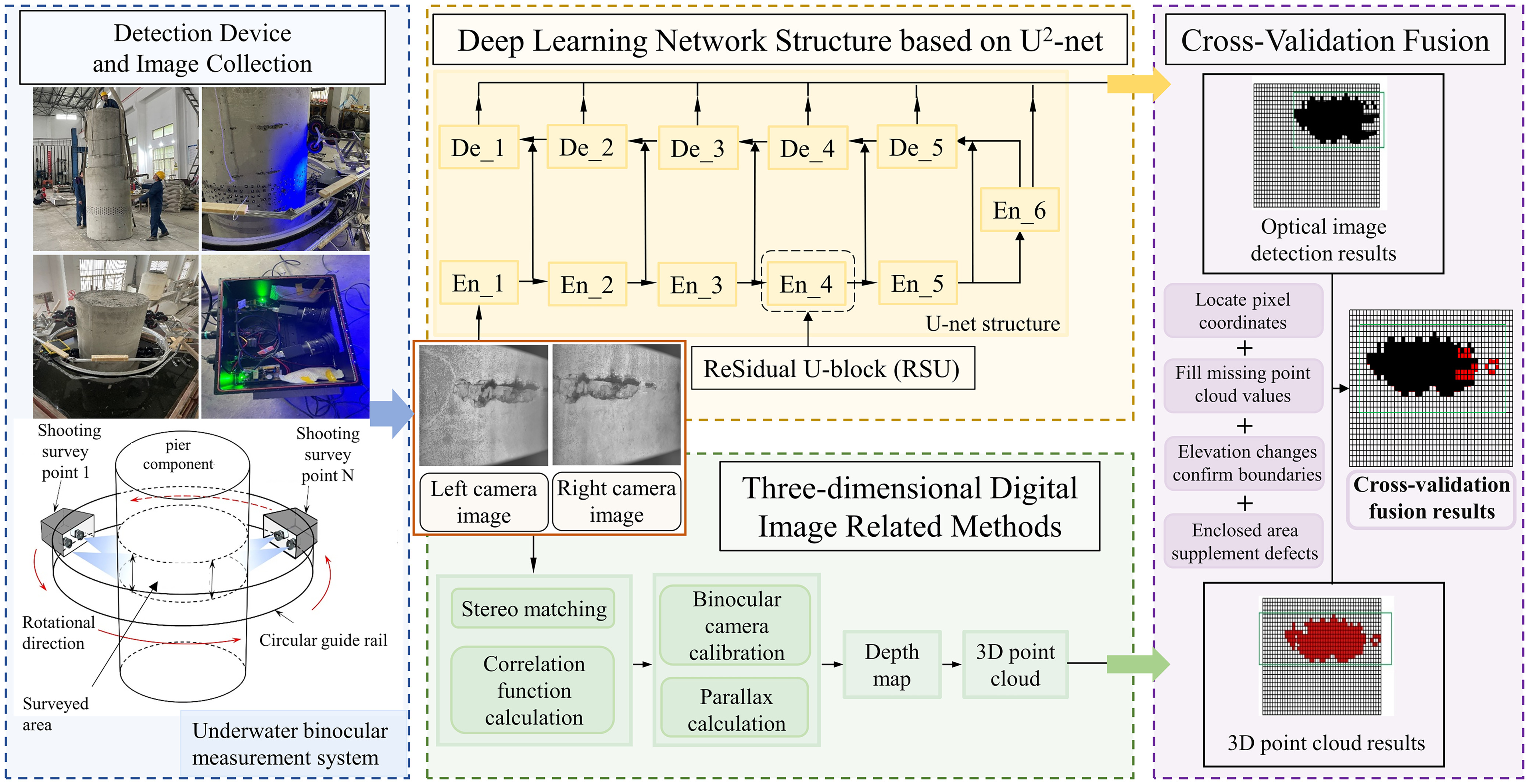
Deep Learning–Based Defect Recognition Model
This study utilizes an encoder–decoder structure from deep learning to perform analysis and research on underwater concrete images of bridges by adopting a multilevel nested U-Net structure (Ronneberger et al. 2015), informed by U2-Net (Qin et al. 2020), to achieve accurate defect recognition and segmentation in underwater concrete imagery. This method addresses the shortcomings of prior techniques that achieved deeper architectural layers at the expense of high-resolution feature maps (Zhang et al. 2018; Hou et al. 2022). The method builds upon and refines the designs of traditional fully convolutional networks and U-Net, overcoming prior limitations in semantic segmentation such as low computational efficiency and the incomplete extraction of contextual information.
Image Acquisition and Defect Classification
Most publicly available underwater image data sets contain only images and annotation files, lacking the physical dimensions of defects. To validate the effectiveness of the proposed method for measuring physical dimensions, experiments were conducted using a self-constructed data set. To create a training data set for deep learning, a 3 m × 3 m × 3 m water tank was set up in a laboratory to mimic underwater inspection conditions, as shown in Fig. 2. A full-scale, concrete bridge pier with variable cross sections was constructed, incorporating typical structural defects like spalling, exposed rebars, and cracks on surface. Considering the specific nature of underwater structural defects, exposed water pipes were designed to account for voids in pipelines (Teng et al. 2024). Calibration papers were affixed to the pier surface to simulate moss and other vegetation defects (Freire et al. 2015; Potenza et al. 2020; Pushpakumara and Thusitha 2021). For underwater bridge structures, vegetation (mainly moss) growth can cause root systems to penetrate microcracks, further enlarging these cracks, accelerating water infiltration, and damaging the durability of concrete bridges (González-Jorge et al. 2012; Conde et al. 2016). Vegetation growth also obscures the observation of other surface defects (such as cracks). To ensure experimental safety, the number of exposed water pipes was limited to four, resulting in a small sample size. Therefore, vegetation and voids in pipeline defects were combined and collectively termed foreign objects. Similarly, there are only four instances of exposed rebars, which often occur concurrently with spalling. Therefore, exposed rebars and spalling are combined and collectively termed spalling and exposed rebars.

To overcome underwater imaging challenges like turbid water, poor lighting, and low resolution, a 20-megapixel complementary metal oxide semiconductor (CMOS) camera (max resolution 5,472 × 3,648) with LED 5050 array lights emitting blue light was employed. Blue light, due to its shorter wavelength, penetrates water better (Chiang and Chen 2012), improving visibility, contrast, and reducing color distortion, consequently enhancing detection accuracy. Fig. 3 illustrates three typical types of defects in the data set. The first row shows defect images taken in air, the second row displays defect images captured underwater, and the third row presents annotated defect images.

U2-Net Neural Network Structure
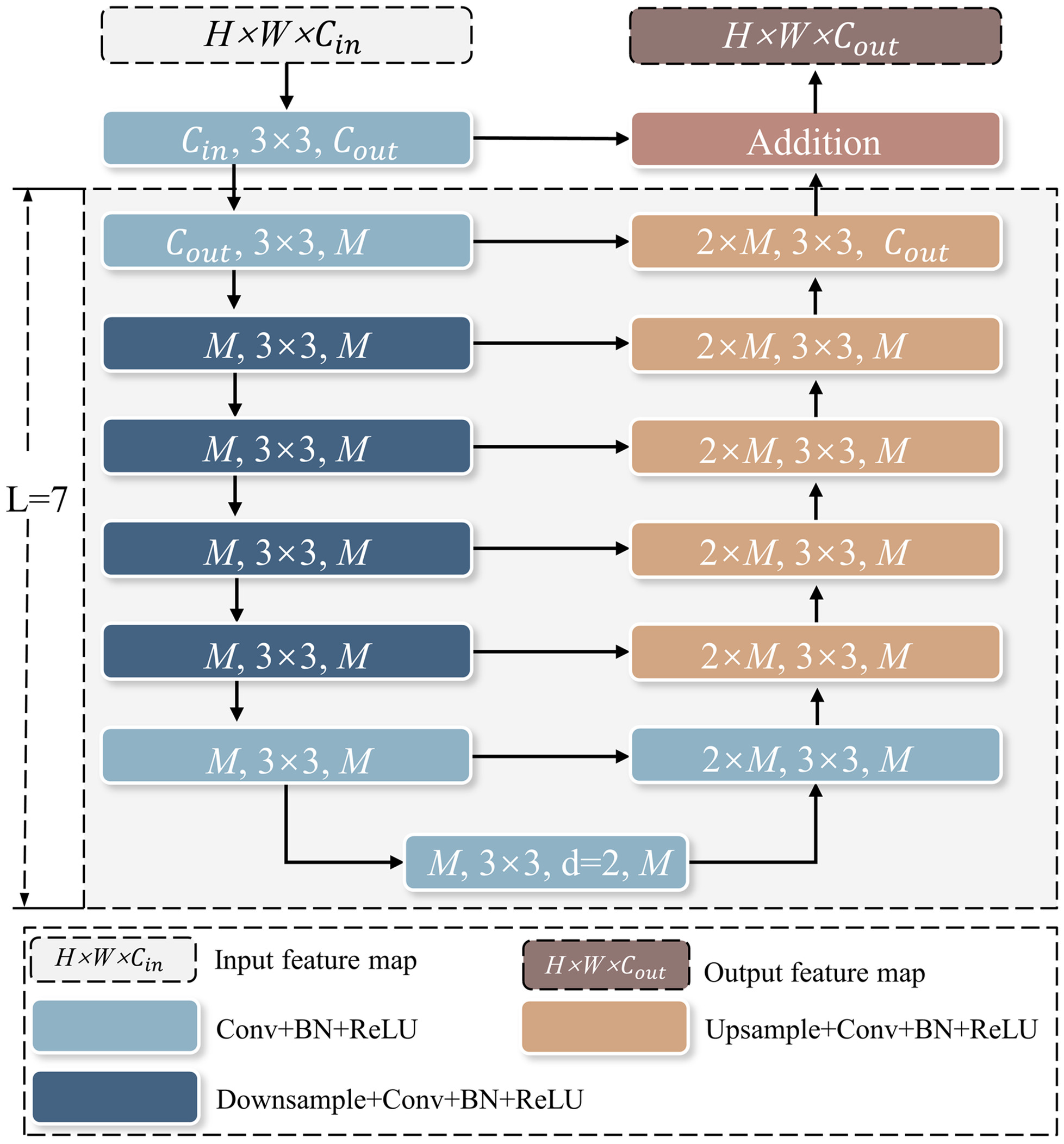
U2-Net is a novel network architecture based on U-Net, which has shown promising results in foreground–background segmentation tasks with small pixel proportions. The new residual U-blocks (RSU) module based on U-Net is an integral part of our neural network encoder–decoder pairs.
The RSU structure used in U2-Net is mainly used to capture multiscale features within each encoder and decoder. The RSU-L (Cin, M, Cout) structure is shown in Fig. 4, where L is the number of layers in the encoder, Cin and Cout represent the input and output channels, respectively, and M represents the number of channels in the internal layer of RSU. RSU first uses the input convolutional layer to transform the input feature map x (H × W × C) into an intermediate map F1(x) with channel Cout. Then, a symmetric encoder–decoder structure similar to U-Net, with a height of L, is used to take the intermediate feature map F1(x) as input to learn to extract and encode multiscale contextual information U[F1(x)]. A larger L will result in more pooling operations, larger receptive field range, and richer local and global features. Finally, the residual connection of local features and multiscale features is fused by summing F1(x) + U[F1(x)]. By adjusting L with different parameters, local features and multiscale features are fused through residual connections to reduce the loss of detail features caused by large-scale upsampling.
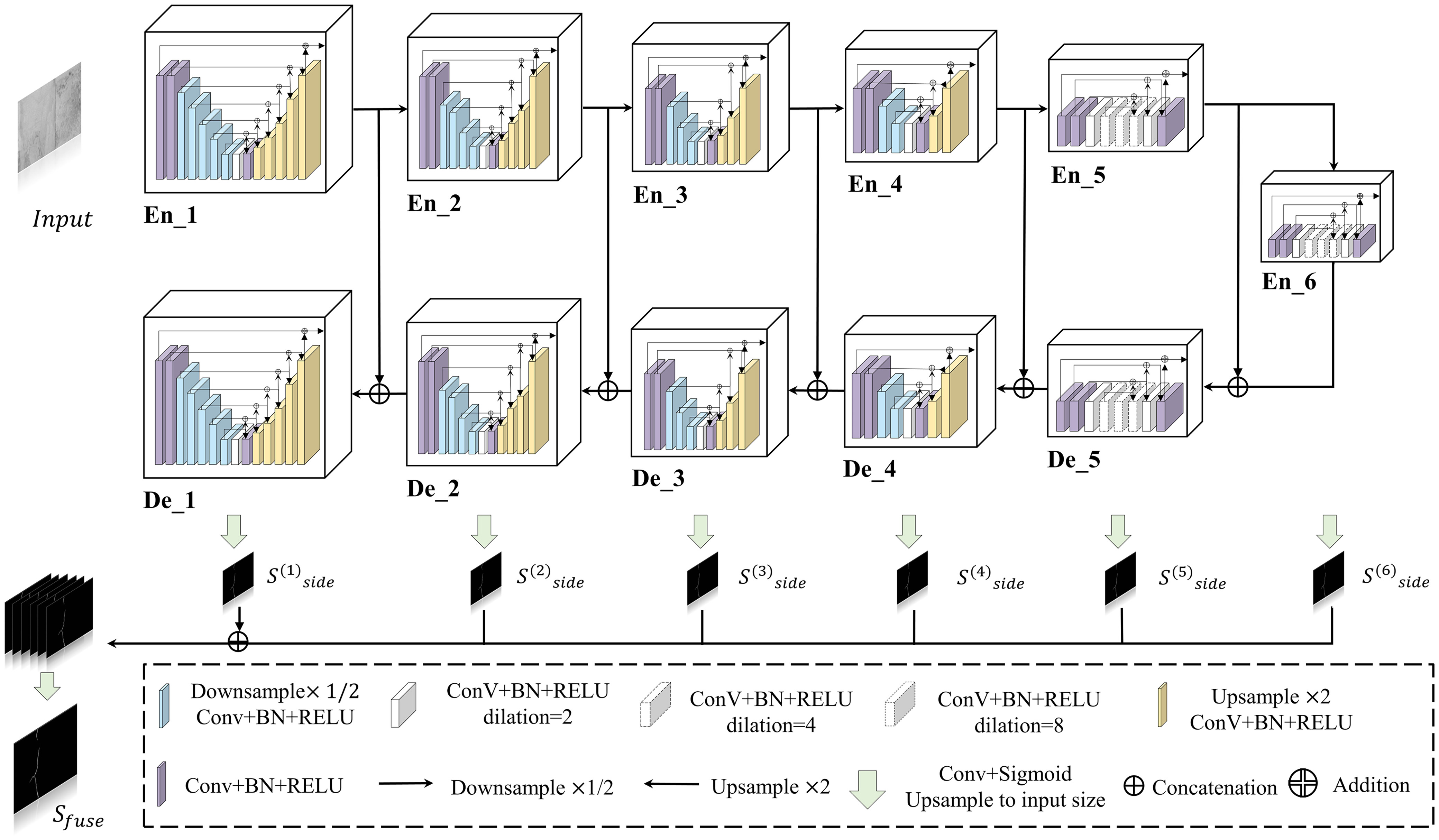
As illustrated in Fig. 5, U2-Net structure consists of six encoders, five decoders, and a saliency map fusion module that interlinks them. This multilevel nested U setup enhances the extraction of multiscale features within each pair and facilitates effective feature aggregation across layers. Encoders 1–4 utilize RSU modules of varying heights (L = 7 to 4) to capture features at different scales. According to the spatial resolution of the input feature maps, L is usually configured. For feature maps with large height and width, greater L is used to capture more large-scale information. The resolution of feature maps in Encoders 5 and 6 are relatively low; further downsampling of these feature maps leads to loss of useful context. Hence, Encoders 5 and 6 adopt dilated version RSU modules with a height of 4 to ensure that the intermediate feature maps have the same resolution as the input feature maps. The decoder stages have similar structures to their symmetrical encoder stages. In Decoder 5, the dilated version RSU module with a height of 4 is also used. Each decoder stage takes the concatenation of the upsampled feature maps from its previous stage and those from its symmetrical encoder stage as the input. The last part is the saliency map fusion module, which is used to generate saliency probability maps. U2-Net first generates six side output saliency probability maps, Sside (6), Sside (5), Sside (4), Sside (3), Sside (2), and Sside (1), from the stages of Encoder 6, Decoder 5, Decoder 4, Decoder 3, Decoder 2, and Decoder 1 by a 3 × 3 convolution layer and a sigmoid function. Then, it upsamples these saliency maps to the input image size and fuses them with a concatenation operation followed by a 1 × 1 convolution layer and a sigmoid function to generate the final saliency probability map Sfuse, as shown in Fig. 5. The neural network model based on U2-Net, using RSU blocks, avoids the need for preadjusted pretrained parameters, ensuring flexibility, reduced performance degradation, and suitability for underwater imaging environments.
Loss Function
In terms of loss function design, the model evaluates not only the output feature maps from the network but also the intermediate fused feature maps. The total loss function L combines weighted losses from multiple side output feature maps and the final feature map, adjusts the weights of cross-entropy loss based on the sample class proportions, and employs the Intersection over Union (IoU) metric as the optimization target for defect segmentation. This approach effectively balances the assessment and optimization needs for multiclassification problems. The formulas are as follows:where = loss of the six side output feature maps; lf = loss of the final feature map; and and wf = respective weights balancing these two losses. The variable ti denotes the true value and f(s)i denotes the normalized exponential function value for each category.
(1)
(2)
Three-Dimensional Point Cloud Reconstruction Based on Three-Dimensional Digital Image Correlation
The reconstruction of 3D morphology of underwater structural surface defects using the 3D DIC method is analogous to aerial 3D reconstruction. By matching the defect edge pixel areas segmented through deep learning with the corresponding positions in the point cloud, the actual physical dimensions of localized defects can be accurately determined, facilitating more precise measurements of these defects.
Principle of Binocular Vision
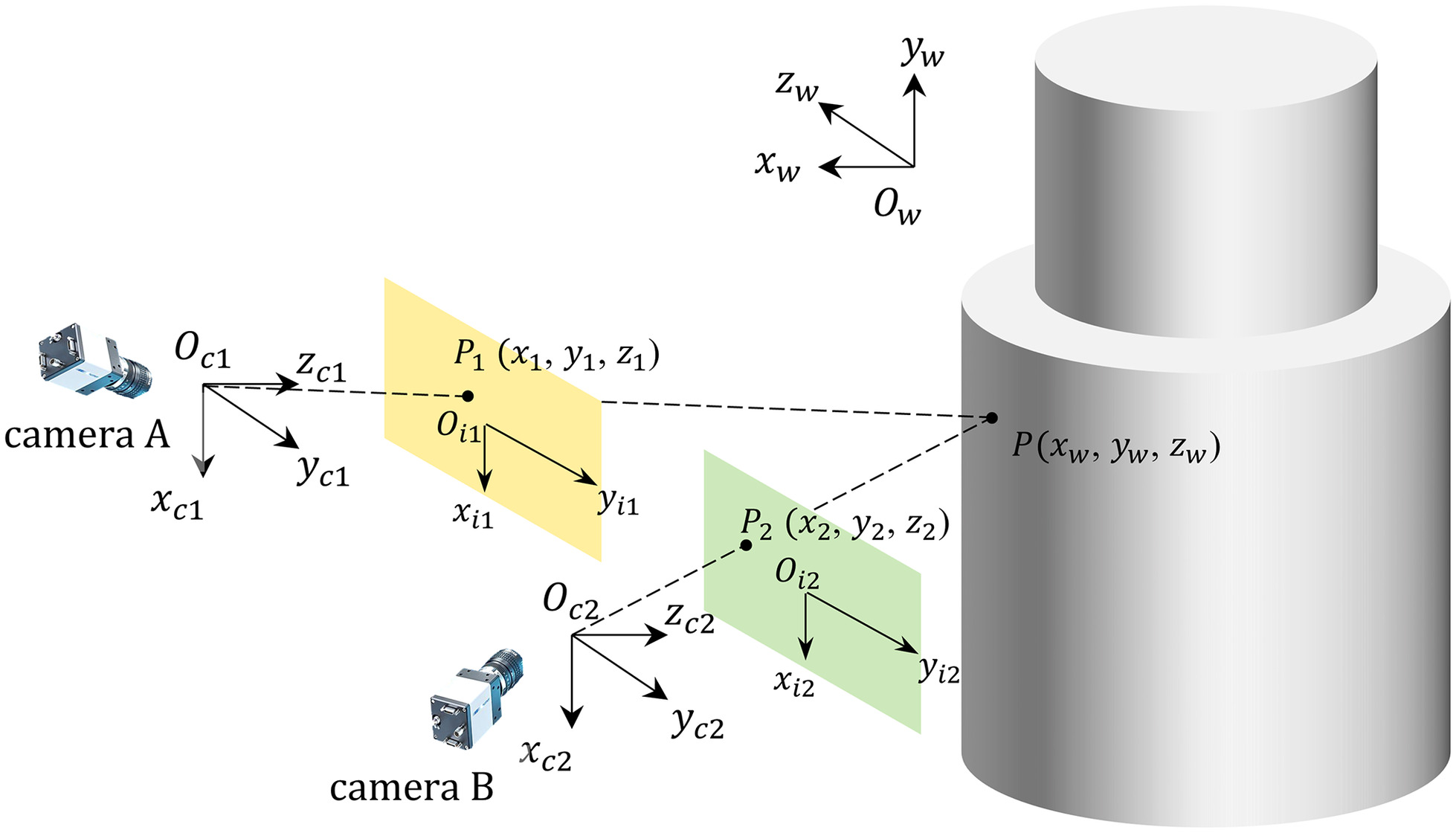
3D digital image correlation measurement is based on the principle of binocular stereovision. Two cameras simultaneously capture images of the same scene from different viewpoints. Corresponding points are then identified in the two 2D images. Using the calibration parameters of the binocular cameras, including the intrinsic and extrinsic parameters and distortion coefficients, the 3D coordinates of the points in the scene can be calculated. As illustrated in Fig. 6, Ow − xwywzw represents the world coordinate system where the spatial point P(xw, yw, zw) is located. Oc − xcyczc and Oi − xiyizi denote the camera coordinate systems and pixel coordinate systems for each camera, respectively. Points P1(x1, y1, z1) and P2(x2, y2, z2) are the projections of point P on the image planes of Cameras A and B, respectively. The optical center Oc1 of Camera A, image point P1, and spatial point P are collinear, as are the optical center Oc2 of Camera B, image point P2, and spatial point P. Therefore, the intersection of lines Oc1 · P1 and Oc2 · P2 determines the 3D coordinates of point P.
Stereo Matching
Stereo matching involves finding corresponding points in the digital images of the object surface recorded by two cameras (Poggi et al. 2021), as shown in Fig. 7. To accurately match image subregions in the left and right views, the selection of shape functions should consider not only the imaging relationship of the cameras but also the height information of the object surface.
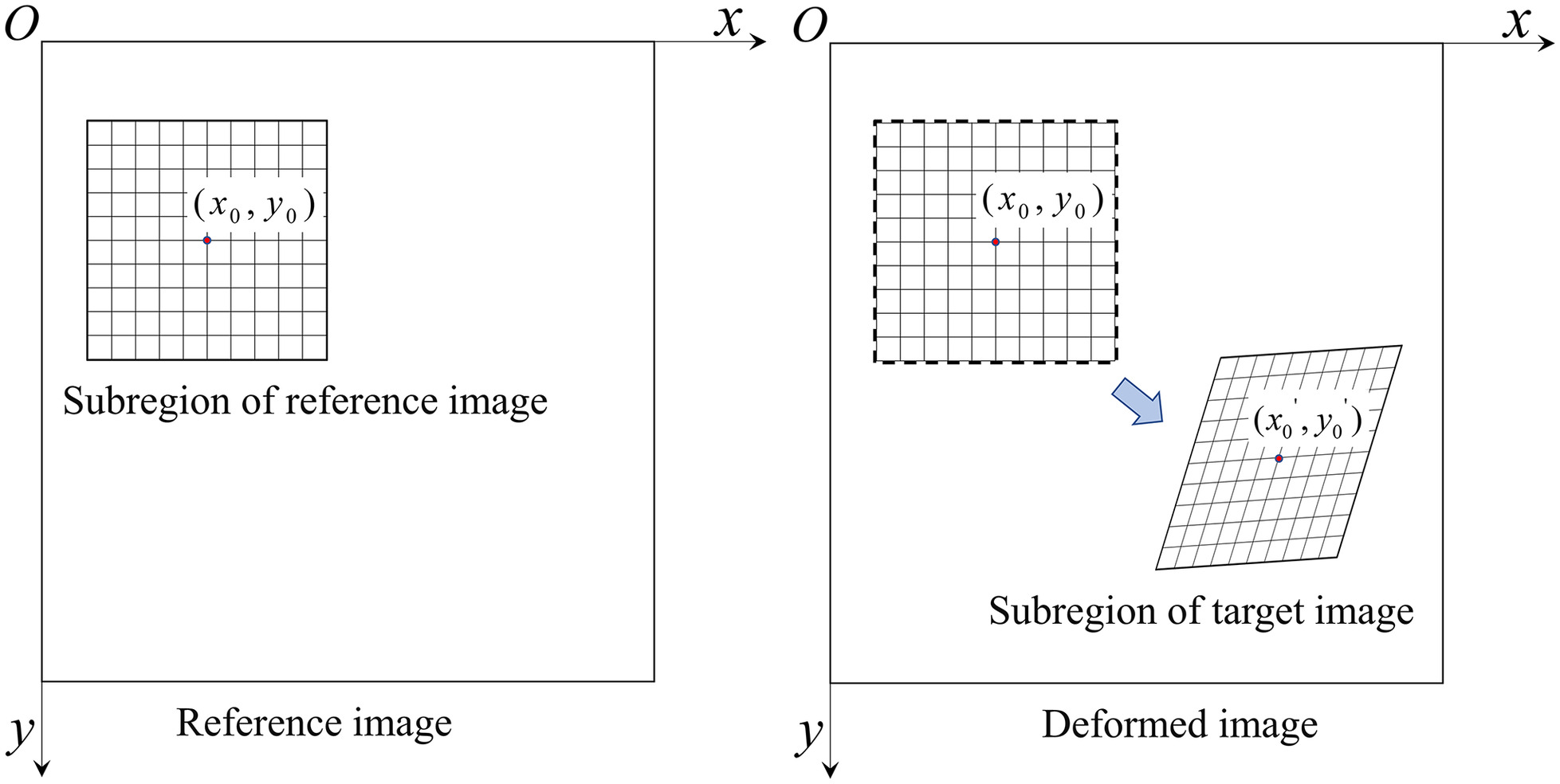
In this paper, the zone-based stereo matching algorithm was selected. This approach selects a subwindow around a pixel point in one image and searches for the most similar subwindow in the other image based on similarity measures. The matched pixel in the corresponding subimage represents the matching point. Given the zero mean normalized cross-correlation (ZNCC) method’s robustness against illumination changes, it is chosen for computing the disparity map. The matching level between subimages and the template is calculated using a normalized correlation formula, which is defined as follows:where f(x, y) and t(x, y) = two vectors to be compared; n = dimensionality of the vectors or the window size; σ = standard deviation of the two samples; and μ = mean of the two samples.
(3)
First, let us designate one image as I1 and the image to be matched as I2, both of size H × W. Then, employing the ZNCC similarity measure formula, a template window size and region T are selected in the left camera image. The template is moved with a specified step size in the right camera image, and the similarity S between the corresponding region and T is calculated, completing one matching calculation. To achieve subpixel image matching and enhance matching accuracy, various nonlinear optimization methods can be utilized for parameter calculation (Bruck et al. 1989; Baker and Matthews 2004). The parameters can be determined based on the correspondence between the same feature point in the left and right images:where x0 and y0 = center point of the template region; δx = x − x0; δy = y − y0; ε0 and η0 = parallaxes between the center points of the right image and the template region in the left image; εx, εy, ηx, and ηy = first-order derivatives of the parallaxes within the template; and εxx, εyy, εxy, ηxx, ηyy, and ηxy = second-order derivatives of the parallaxes within the template.
(4)
(5)
The maximum similarity S in the current matching calculation result is selected as the most matching position. Then, the horizontal distance difference between the left image and the pixel at the most matching position in the image to be matched is computed as the parallax value corresponding to the current pixel.
Three-Dimensional Point Cloud Reconstruction
By calibrating the binocular cameras, the parameters of the camera system are obtained. Using the DIC method, corresponding points in the images from both cameras are accurately matched (Ge et al. 2024). Alongside camera calibration, the stereo cameras establish a spatial world coordinate system based on a calibration template, allowing for the reconstruction of 3D spatial coordinates of interest points. After obtaining the parameters and distortion coefficients of both cameras, the projection matrices M1 and M2 for the left and right cameras can be calculated as follows:where (u1, v1) and (u2, v2) = homogeneous coordinates of a point on the ideal image plane of the object surface in the left and right cameras, respectively; (xw, yw, zw, 1) = homogeneous coordinate of the point in the world coordinate system; and mij(i = 1, 2, …, j = 1, 2, …) = element in the ith row and jth column of the projection matrix. By eliminating Zc1 and Zc2 from the aforementioned two equations, the following four linear equations regarding the spatial coordinates (xw, yw, zw, 1) were obtained:
(6)
(7)
(8)
(9)
(10)
(11)
From the aforementioned equations, an overdetermined equation is formed. Due to the inevitable presence of noise in the actual data, the least squares method is employed to compute the three-dimensional coordinates of the spatial points. By repeating the aforementioned process for all matched point pairs in the reference images, the spatial coordinates of points on the surface of the measured area can be obtained, thus yielding the three-dimensional point cloud of the measured object’s surface.
Structural Surface Defect Measurement Based on Fusion of Semantic Segmentation and 3D Point Cloud
After segmenting underwater image-based defects using deep learning models, calculating the actual physical dimensions of pathologies from segmented image edges becomes necessary. For above-water structural inspections, methods like laser ranging or affixing markers on surfaces to map pixels to physical dimensions are common. However, these approaches are not feasible underwater. Instead, a binocular stereovision–based method is employed for mapping pixels to their physical dimensions.
Once the correspondence between three-dimensional space and the image is established, stereo matching techniques clarify the relationship between points in the left and right images, enabling parallax calculation and recovery of three-dimensional point information. This process involves underwater binocular camera calibration, image rectification, stereo matching, and the computation of depth and point cloud. The physical dimensions of localized pathologies are obtained by matching the deep learning–segmented edge pixels with their corresponding positions in the point cloud, as outlined in Fig. 8. The binocular camera’s intrinsic parameters are calculated using Zhang’s chessboard calibration method (Chen and Pan 2020). Image rectification includes epipolar correction and distortion correction, aligning the pixels row-wise across both camera images. The binocular parallel rectification aligns camera coordinate systems with the world coordinate system, followed by epipolar alignment using rotation matrices R1 and R2, and distortion correction. Finally, the camera coordinate system is converted back to pixel coordinates using the intrinsic matrix, with pixel values from the original coordinates assigned to the new image coordinates.
The parallax map of the entire image is obtained through stereo matching, and then the actual depth map is calculated using the following formula:where depth = depth value; fc = normalized focal length of the intrinsic parameters; = distance between the optical centers of the binocular cameras; and disp = parallax.
(12)
Therefore, the point cloud coordinates of each pixel are calculated as follows:where u and v = image pixel coordinates; s = camera scaling factor; and fx, fy, Cx, and Cy = calibrated camera intrinsic parameters.
(13)
Upon acquiring point cloud data, the coordinates for each pixel’s corresponding point in the cloud are known. By using deep learning models to identify the coordinates of pixels at the edges of lesions, the spatial three-dimensional coordinates of these edge pixels within the point cloud can be found. Projecting these coordinates onto the image plane allows us to delineate the polygonal areas of pathology formed by point cloud data on this plane, as depicted in Fig. 9. Based on the Shoelace theorem (Braden 1986), given the vertices’ coordinates, the area of any polygon can be calculated as follows:where x and y = pixel coordinates on the image plane.
(14)
Experimental Results Analysis
In the full-scale bridge pier components fabricated under laboratory conditions, defects such as cracks, spalling, exposed rebars, and foreign objects were designed. A total of 1,734 underwater component images were collected in the laboratory. The data set samples were randomly split into training, validation, and test sets at a ratio of 8:1:1. The Adam optimization algorithm was chosen for model training with a learning rate of 0.0001 over 70 total epochs, adjusting the learning rate to 95% of the previous step at epochs 10, 20, 30, 40, and 50. To validate the model’s effectiveness, the original U-Net network structure was employed for comparison. The analysis of existing underwater image data revealed a ratio of 15 (exposed rebars): 368 (spalling and exposed rebars) samples, with only 4 effective samples. Specifically, there are four instances of exposed rebars on the bridge piers, with 15 images depicting exposed rebars and 368 images showing spalling and exposed rebars. Considering the shortage of exposed rebar samples and the fact that exposed rebar often co-occurs with spalling, both were treated as the same detection category, resulting in three practical detection categories: cracks, spalling and exposed rebars, and foreign objects.
Defect Segmentation Results
Considering the limited sample data for crack defects and the high resolution of the imaging equipment used in this study, a sliding window strategy was employed to augment the collected image data set. The sliding window size was set at 544 × 544 pixels, with a stride of 256, resulting in 1,157 crack training images. The data set also included 368 samples of spalling and exposed rebar images, with minimum and maximum bounding box sizes ranging from 3 × 3 to 1,928 × 1,652 pixels, indicating a wide variation in target sizes. To detect small targets and accommodate the semantic needs of larger objects, the network input size was increased to 1,024 × 1,024. The training data for the spalling and exposed rebars category were generated using a window size equal to half the original dimensions of the images, without considering overlap, producing 1,146 samples. Additionally, 180 foreign object samples were processed similarly, with an average effective foreground pixel ratio of 0.0986, yielding 465 samples. The number of data set samples is presented in Table 1.
| Category | Original number | Expanded number |
|---|---|---|
| Spalling and exposed rebars | 368 | 1,146 |
| Foreign object | 180 | 465 |
| Crack | 109 | 1,157 |
Table 2 presents the final test comparison results between two groups of models. The data indicate that both model groups exhibit good predictive performance for detecting foreign objects and spalling and exposed rebars, with U2-Net achieving pixel accuracy rates of 0.943 for foreign objects and 0.811 for spalling and exposed rebars. In terms of IoU comparisons for segmentation results, U2-Net significantly outperforms with scores of 0.733 for foreign objects and 0.411 for spalling and exposed rebars, reaching a mean intersection over union (mIoU) of 0.548. U-Net, however, shows weaker performance in IoU, with an mIoU of only 0.503. Nevertheless, both models underperform in crack detection due to the extremely low proportion of crack pixels as foreground targets against the background, accounting for just 0.464%, leading to poor detection results. This issue is primarily attributed to the high difficulty of observing cracks underwater, influenced by surrounding features and the limited size of sample populations. Errors in manual annotation, inconsistent labeling standards, and the small scale of crack samples contribute to the inferior results for crack detection.
| Category | Metric | Model | |
|---|---|---|---|
| U2-Net | U-Net | ||
| Background | Recall | 0.999 | 0.999 |
| PA | 0.992 | 0.987 | |
| IoU | 0.991 | 0.986 | |
| Crack | Recall | 0.272 | 0.193 |
| PA | 0.151 | 0.121 | |
| IoU | 0.093 | 0.056 | |
| Foreign object | Recall | 0.876 | 0.720 |
| PA | 0.943 | 0.958 | |
| IoU | 0.733 | 0.609 | |
| Spalling and exposed rebars | Recall | 0.466 | 0.352 |
| PA | 0.811 | 0.854 | |
| IoU | 0.411 | 0.325 | |
| mIoU (c) | 0.548 | 0.503 | |
| mIoU | 0.711 | 0.640 | |
Note: (c) = The mean IoU that includes cracks; and PA = Pixel accuracy.
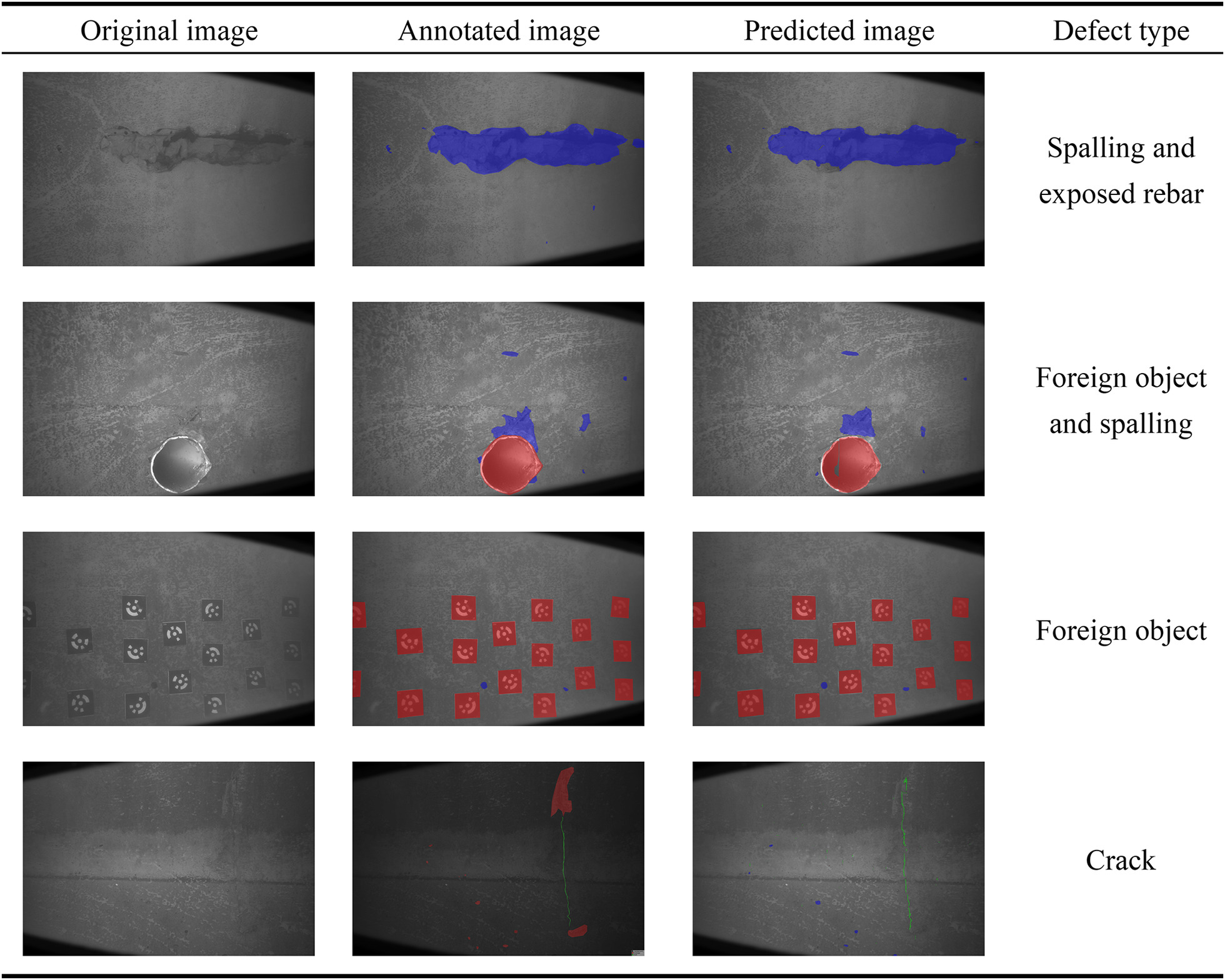
To evaluate the performance and segmentation effects of the U2-Net model, this study selected several representative images based on defect type, distribution location, and defect area size, as shown in Fig. 10. The results indicate that the model based on U2-Net proposed in this study successfully identifies various types of defect information in underwater images, extracting defect category and distribution location from images taken from two angles by left and right cameras. The model was trained with images including two types of foreign objects, which could be accurately segmented owing to their distinct features on the concrete surface. Moreover, the model precisely located and segmented large-area defects at different positions and recognized small-area defects effectively, although the segmentation accuracy for small defects was poorer compared to large-area defects, and there were some variations in segmentation results for the same defect from different angles. Additionally, the model can recognize multiple types of information simultaneously through the underwater defect segmentation inference process. In terms of crack detection, the model effectively detects long cracks due to the quantity of crack samples but performs poorly in recognizing and segmenting fine cracks and similar defects, resulting in some misjudgments.
The results of defect segmentation are presented in Fig. 11. The highest recognition accuracy was observed for foreign objects, with a segmentation accuracy (IoU) for large-area defects reaching 0.8642. By contrast, smaller defects exhibited an IoU of approximately 0.6. The IoU for cracks was only 0.2404, which, relative to the resolution of the entire image at 3,648 × 5,472, accounts for a mere 0.258% of predicted crack pixels. This is primarily because of the limited number of training samples for underwater crack defects. Taking spalling defects as an example, the pixel proportion in the third row of Fig. 11 is only 0.11%. However, analysis of spalling defect characteristics reveals that they mainly manifest as continuous black areas. As shown in Fig. 12, compared to the slender nature of cracks, the characteristics of spalling are more easily distinguished from the surrounding texture features. Thus, further research is necessary for the precise recognition of minor surface cracks in components.
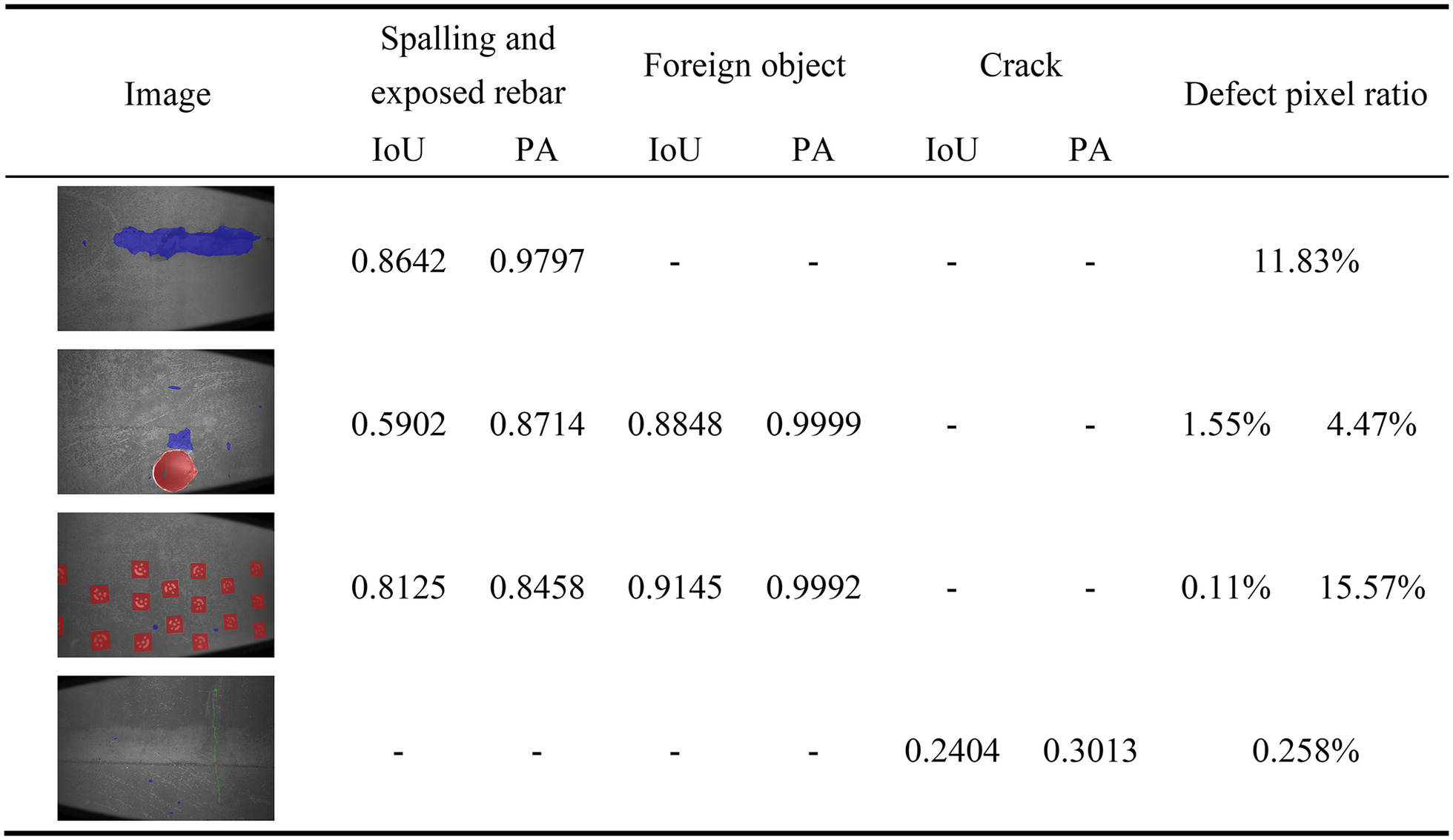

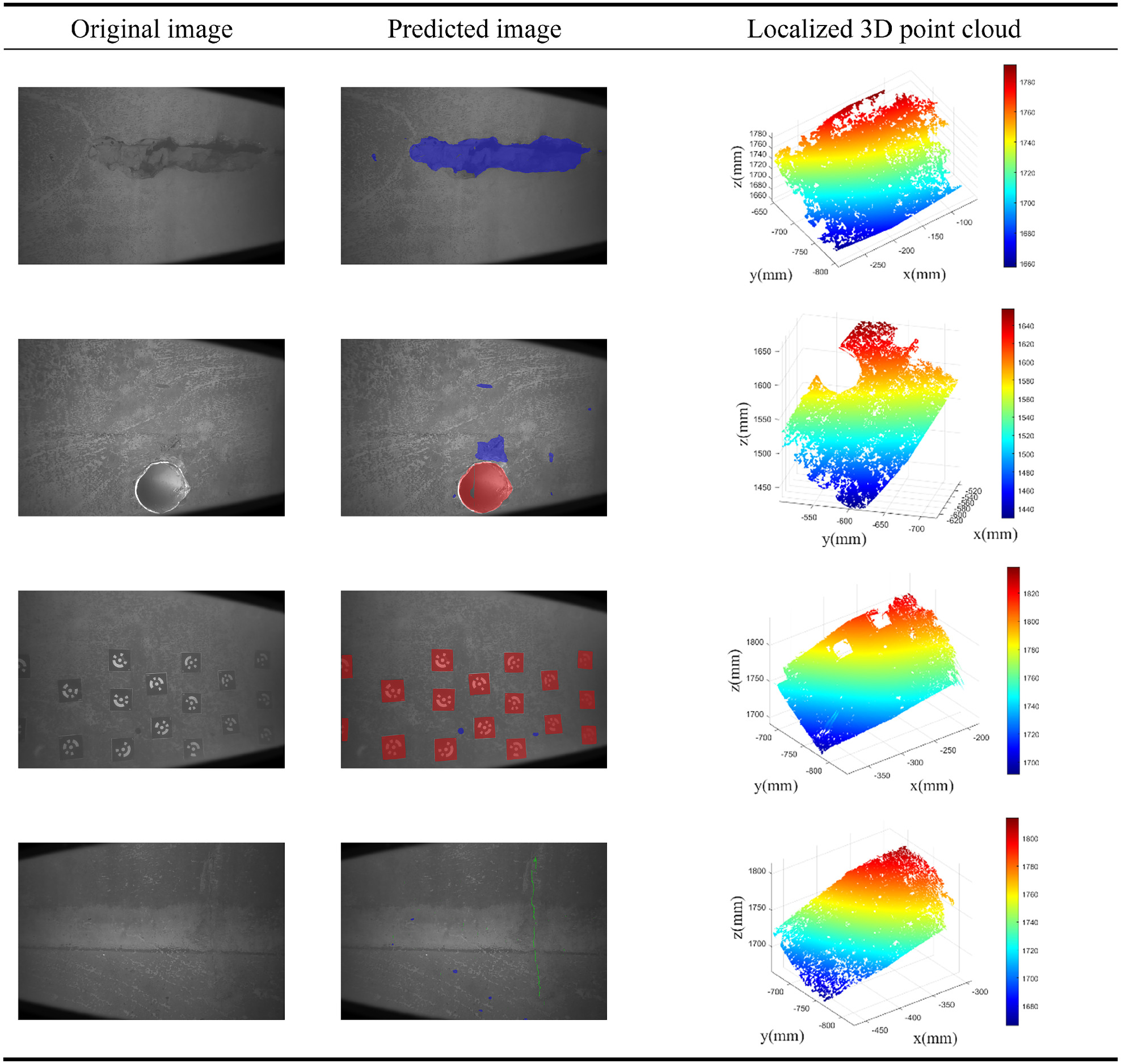
Defect Three-Dimensional Point Cloud Measurement Results
The point cloud reconstruction results, as shown in Fig. 13, indicate partial completeness due to the weak texture features of concrete surfaces. While large-area defects’ point cloud accurately depicts contour information, regions with significant surface undulations cannot be reconstructed due to the limited depth of field of binocular cameras. The reconstructed areas offer more precise contour information compared to defect detection results. The point cloud reconstructions of foreign object defects match the defect detection outcomes, achieving high measurement accuracy and distinct separation from other surface areas. This allows for the calculation of foreign object areas through the one-to-one correspondence between point clouds and image pixels. However, for minor defects such as cracks, the point cloud results are not as discernible, with fine cracks potentially obscured by point cloud interpolation, preventing accurate measurement of crack dimensions. Hence, further research into precise recognition of minor surface cracks is warranted.
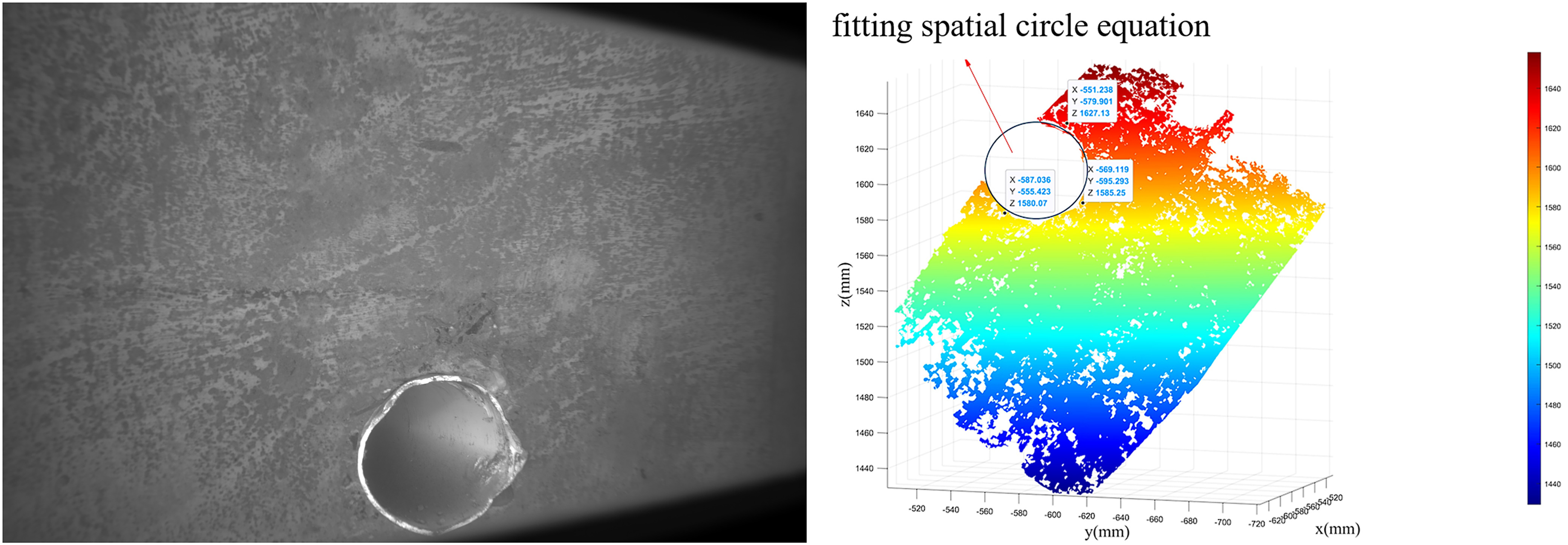
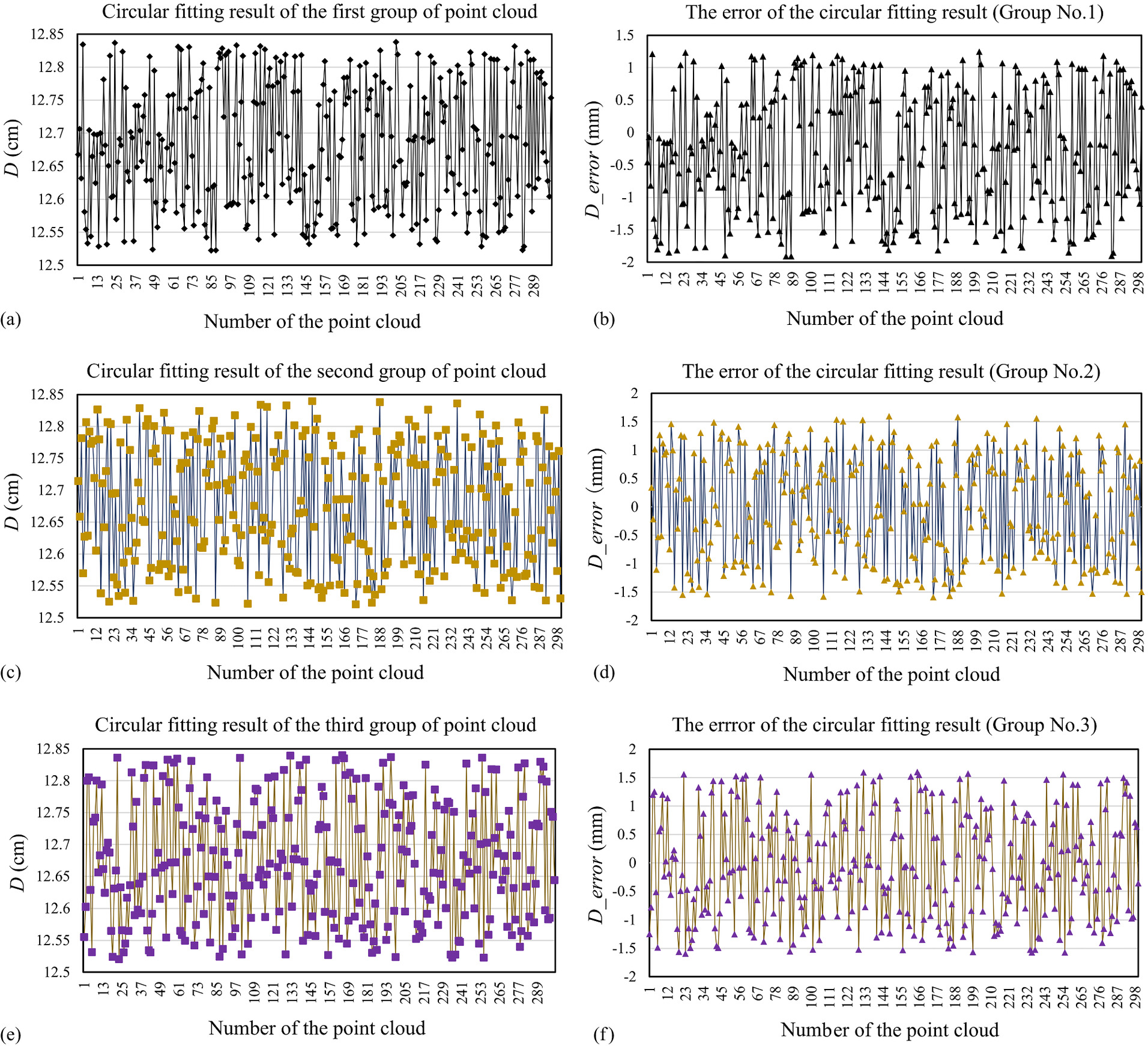
The experimental results show that the point cloud reconstruction accuracy error of large-area defects is at the millimeter level. Taking the measurement of foreign objects as an example, the diameter of a roughly circular exposed water pipe opening on a concrete bridge pier was measured prior to the experiment, with an inherent manufacturing error. Based on multiple measurements, the average diameter was calculated to be 12.7 cm. As shown in Fig. 14, 900 points were selected along the circumference of the pipe opening’s point cloud morphology and divided into three groups for spatial circle fitting. The fitted diameters of the three circles were 12.7132, 12.7516, and 12.5497 cm, respectively. The diameter for each point was taken as twice the distance from the point to the center of the fitted circle. Fig. 15 illustrates the diameter size corresponding to each point and the respective diameter error, where D represents the diameter. The maximum value of the average diameter error was 1.837 mm, and the standard deviations were 0.8121, 0.9357, and 1.0461 mm, respectively. The analysis suggests that although the 3D DIC–based point cloud reconstruction is limited by the depth of field of the binocular camera, preventing the whole area of defect reconstruction, it demonstrates significant advantages in accurately locating defect edges or contours, achieving excellent measurement precision.
Analysis of Localized Defect Measurement Results by Fusion of Segmentation Results and Point Cloud Information
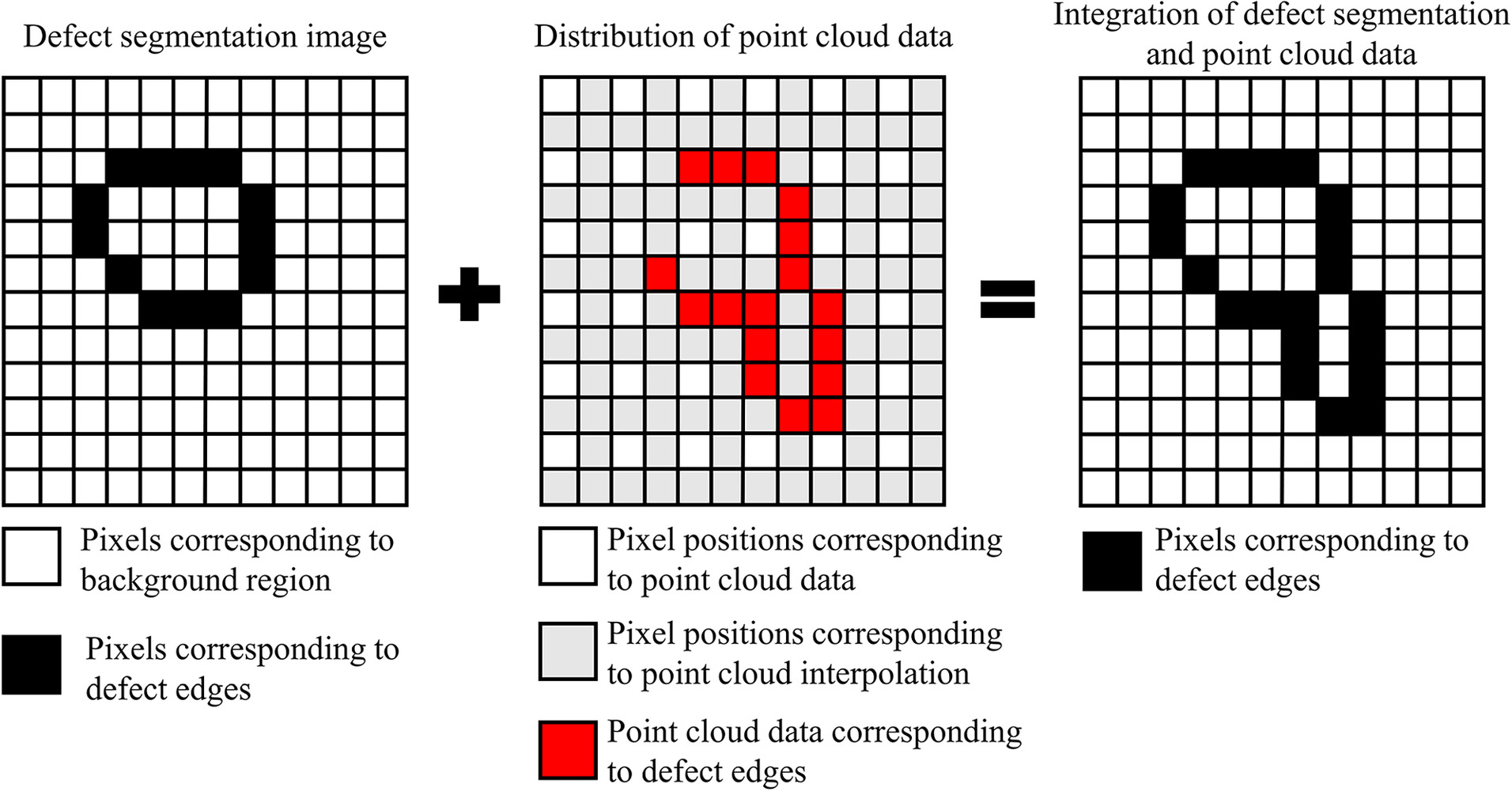
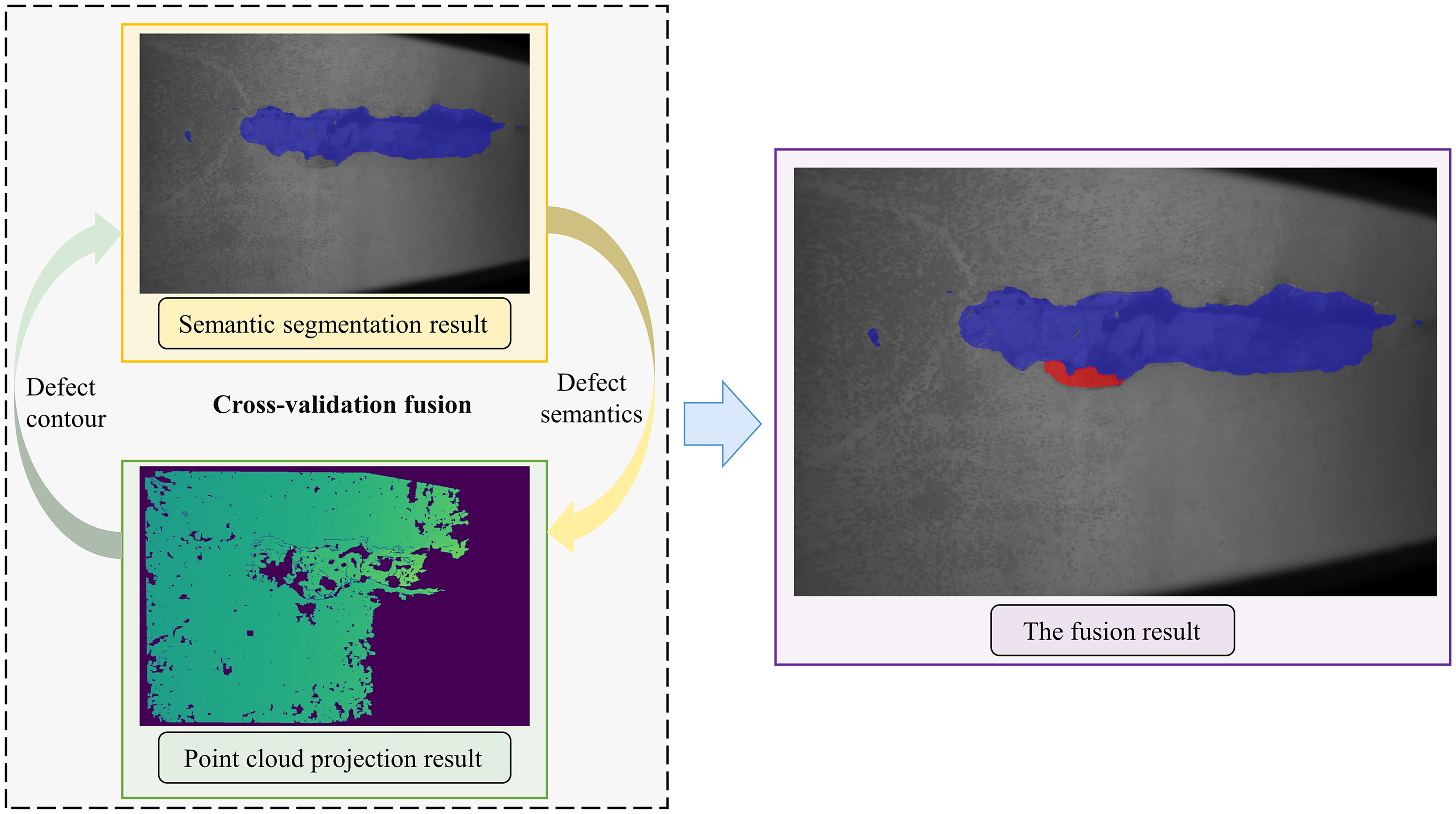
Upon obtaining the segmentation results of the defects, a quantitative measurement of the defects listed in the figure was performed using a stereovision-based measurement method. Due to the precision of matching calculations, the initial point cloud data contain some voids, including unsolved null values and defect areas. To accurately identify defect information in the point cloud, it can be discerned based on the results of deep learning segmentation. Moreover, the segmentation results reveal localized errors in the pixel distribution of the segmented defect areas, with some pixels misclassified as background or defect. Now, by fusing both, further accurate segmentation and measurement of defect locations are achieved, that is, obtaining the actual defect locations from the deep learning model’s segmentation results and correcting the segmentation results through the point cloud values of that area, ultimately calculating the actual defect plane dimensions from the corresponding point cloud data post fusion. Therefore, taking the defect images obtained and calculated from the aforementioned experiments as examples, the following process implements precise measurement of defects:
1.
Based on the deep learning segmentation results, locate the defect areas in the image by obtaining the pixel coordinates of the defect boundaries.
2.
Further refine the deep learning segmentation results by adding missing defect pixels within the closed areas formed by the existing point cloud. Next, use the elevation change data from the point cloud to delineate the pixel boundaries between defective and intact areas, and remove misjudged background areas accordingly.
3.
For the missing parts of the point cloud, based on the segmentation results of the deep learning model, the missing point cloud values corresponding to the edge pixel sequences are filled in with neighboring values.
4.
Based on the fused defect area position, calculate the specific size of the defect using the point cloud coordinate values. According to the aforementioned fusion criteria and process, the final recognition results of the defect image are shown in Fig. 16. Based on Eq. (14), the defect area of the plane projection area is calculated as 105.68 cm2.
Conclusions
Accurate identification and quantification of surface defects in underwater bridge structures are of great significance for understanding the structural damage of these underwater components. This paper proposes a method for precise and intelligent detection of defects in underwater bridge substructures, fusing deep learning with 3D point cloud. It proposes a method for identifying surface defects of underwater structures using the U2-Net neural network architecture and for reconstructing localized defects using 3D point cloud. By fusing deep learning semantic segmentation results with 3D point cloud reconstructions, it achieves refined quantitative recognition of localized defects on the surfaces of underwater bridge components.
The neural network model based on U2-Net can effectively identify defects at different locations, including those at the edge of the image or with low resolution. By correcting the elevation changes in the point cloud, the method can more accurately segment large-area defects and also effectively identify smaller defects. It achieves pixel accuracies of 0.943 for foreign objects and 0.811 for spalling and exposed rebars, and IoUs of 0.733 and 0.411, respectively. In addition, the physical size of the defect, including length and area, can be accurately measured through the principle of binocular vision, with an accuracy of up to millimeter level. After combining with the segmentation results, the semantic information of the defect can be accurately obtained.
Although this study presents promising results for intelligent detection and physical dimension measurement of surface defects of underwater bridge structures, several unresolved issues merit attention in future research. First, considering that water quality is often turbid and contains impurities during actual engineering inspections, future research should further investigate detection effectiveness under various water turbidity levels to validate the robustness of the proposed method. Second, the deep learning model should be further improved to enhance its ability to identify and segment subtle defects. Finally, the underwater imaging model needs improvement to account for multiple reflections and refractions of underwater light, to more accurately restore point cloud depth information and reduce distortion.
Data Availability Statement
Some or all data, models, or codes that support the findings of this study are available from the corresponding author upon reasonable request.
Acknowledgments
The research was financially supported by the National Natural Science Foundation of China (52127813 and 52208306), the Natural Science Foundation of Jiangsu Province (BK20220849), and the Jiangsu Provincial Key Research and Development Program (BE2022820).
References
Abdallah, A. M., R. A. Atadero, and M. E. Ozbek. 2022. “A state-of-the-art review of bridge inspection planning: Current situation and future needs.” J. Bridge Eng. 27 (2): 03121001. https://doi.org/10.1061/(ASCE)BE.1943-5592.0001812.
Alipour, M., D. K. Harris, and G. R. Miller. 2019. “Robust pixel-level crack detection using deep fully convolutional neural networks.” J. Comput. Civ. Eng. 33 (6): 04019040. https://doi.org/10.1061/(ASCE)CP.1943-5487.0000854.
Baker, S., and I. Matthews. 2004. “Lucas-Kanade 20 years on: A unifying framework.” Int. J. Comput. Vision 56: 221–255. https://doi.org/10.1023/B:VISI.0000011205.11775.fd.
Braden, B. 1986. “The surveyor's area formula.” Coll. Math. J. 17 (4): 326–337. https://doi.org/10.1080/07468342.1986.11972974.
Bruck, H. A., S. R. McNeill, M. A. Sutton, and W. H. Peters. 1989. “Digital image correlation using Newton-Raphson method of partial differential correction.” Exp. Mech. 29: 261–267. https://doi.org/10.1007/BF02321405.
Cardellicchio, A., S. Ruggieri, A. Nettis, V. Renò, and G. Uva. 2023. “Physical interpretation of machine learning-based recognition of defects for the risk management of existing bridge heritage.” Eng. Fail. Anal. 149: 107237. https://doi.org/10.1016/j.engfailanal.2023.107237.
Cha, Y.-J., W. Choi, and O. Büyüköztürk. 2017. “Deep learning-based crack damage detection using convolutional neural networks.” Comput.-Aided Civ. Infrastruct. Eng. 32 (5): 361–378. https://doi.org/10.1111/mice.12263.
Chen, B., and B. Pan. 2020. “Camera calibration using synthetic random speckle pattern and digital image correlation.” Opt. Lasers Eng. 126: 105919. https://doi.org/10.1016/j.optlaseng.2019.105919.
Chen, D., W. Guo, B. Wu, and J. Shi. 2023. “Service life prediction and time-variant reliability of reinforced concrete structures in harsh marine environment considering multiple factors: A case study for Qingdao Bay Bridge.” Eng. Fail. Anal. 154: 107671. https://doi.org/10.1016/j.engfailanal.2023.107671.
Chiang, J. Y., and Y.-C. Chen. 2012. “Underwater image enhancement by wavelength compensation and dehazing.” IEEE Trans. Image Process. 21 (4): 1756–1769. https://doi.org/10.1109/TIP.2011.2179666.
Choi, W., and Y.-J. Cha. 2020. “SDDNet: Real-time crack segmentation.” IEEE Trans. Ind. Electron. 67 (9): 8016–8025. https://doi.org/10.1109/TIE.2019.2945265.
Conde, B., S. Del Pozo, B. Riveiro, and D. González-Aguilera. 2016. “Automatic mapping of moisture affectation in exposed concrete structures by fusing different wavelength remote sensors.” Struct. Control Health Monit. 23 (6): 923–937. https://doi.org/10.1002/stc.1814.
Dekel, T., C. Gan, D. Krishnan, C. Liu, and W. T. Freeman. 2018. “Sparse, smart contours to represent and edit images.” In Proc., the Institute of Electrical and Electronics Engineers Conf. on Computer Vision and Pattern Recognition, 3511–3520. Piscataway, NJ: IEEE.
Dong, Z., G. Wu, X.-L. Zhao, H. Zhu, and X. Shao. 2019. “Behaviors of hybrid beams composed of seawater sea-sand concrete (SWSSC) and a prefabricated UHPC shell reinforced with FRP bars.” Constr. Build. Mater. 213: 32–42. https://doi.org/10.1016/j.conbuildmat.2019.04.059.
Freire, L. M., J. de Brito, and J. R. Correia. 2015. “Inspection survey of support bearings in road bridges.” J. Perform. Constr. Facil. 29 (4): 04014098. https://doi.org/10.1061/(ASCE)CF.1943-5509.0000569.
Ge, P., Y. Wang, J. Zhou, and B. Wang. 2024. “Point cloud optimization of multi-view images in digital image correlation system.” Opt. Lasers Eng. 173: 107931. https://doi.org/10.1016/j.optlaseng.2023.107931.
González-Jorge, H., D. Gonzalez-Aguilera, P. Rodriguez-Gonzalvez, and P. Arias. 2012. “Monitoring biological crusts in civil engineering structures using intensity data from terrestrial laser scanners.” Constr. Build. Mater. 31: 119–128. https://doi.org/10.1016/j.conbuildmat.2011.12.053.
Gu, L., W. Gong, X. Shao, J. Chen, Z. Dong, G. Wu, and X. He. 2021. “Real time measurement and analysis of full surface cracking characteristics of concrete based on principal strain field.” Chin. J. Theor. Appl. Mech. 53 (7): 1962–1970. https://doi.org/10.6052/0459-1879-21-107.
Ho, H.-N., K.-D. Kim, Y.-S. Park, and J.-J. Lee. 2013. “An efficient image-based damage detection for cable surface in cable-stayed bridges.” NDT & E Int. 58: 18–23. https://doi.org/10.1016/j.ndteint.2013.04.006.
Hou, S., J. Dai, B. Dong, H. Wang, and G. Wu. 2022. “Underwater inspection of bridge substructures using sonar and deep convolutional network.” Adv. Eng. Inf. 52: 101545. https://doi.org/10.1016/j.aei.2022.101545.
Iizuka, S., E. Simo-Serra, and H. Ishikawa. 2017. “Globally and locally consistent image completion.” ACM Trans. Graphics 36 (4): 1–14. https://doi.org/10.1145/3072959.3073659.
Kim, B., and S. Cho. 2019. “Image-based concrete crack assessment using mask and region-based convolutional neural network.” Struct. Control Health Monit. 26 (8): e2381. https://doi.org/10.1002/stc.2381.
Li, N., W. Ma, L. Li, and C. Lu. 2019. “Research on detection algorithm for bridge cracks based on deep learning.” Acta Autom. Sin. 45 (9): 1727–1742. https://doi.org/10.16383/j.aas.2018.c170052.
Li, X., Q. Meng, M. Wei, H. Sun, T. Zhang, and R. Su. 2023. “Identification of underwater structural bridge damage and BIM-based bridge damage management.” Appl. Sci. 13 (3): 1348. https://doi.org/10.3390/app13031348.
Liu, Z., Y. Cao, Y. Wang, and W. Wang. 2019. “Computer vision-based concrete crack detection using U-net fully convolutional networks.” Automat. Constr. 104: 129–139. https://doi.org/10.1016/j.autcon.2019.04.005.
Liu, C., S. Dong, M. Mokhtar, X. He, J. Lu, and X. Wu. 2016. “Multicamera system extrinsic stability analysis and large-span truss string structure displacement measurement.” Appl. Opt. 55 (29): 8153–8161. https://doi.org/10.1364/AO.55.008153.
Minaee, S., Y. Y. Boykov, F. Porikli, A. J. Plaza, N. Kehtarnavaz, and D. Terzopoulos. 2021. “Image segmentation using deep learning: A survey.” IEEE Trans. Pattern Anal. Mach. Intell. 44 (7): 3523–3542. https://doi.org/10.1109/TPAMI.2021.3059968.
MOT (Ministry of Transport of the People's Republic of China). 2024. “Transportation overview.” Accessed June 20, 2024. https://www.mot.gov.cn/jiaotonggaikuang/201804/t20180404_3006639.html.
Pan, B., K. Qian, H. Xie, and A. Asundi. 2009. “Two-dimensional digital image correlation for in-plane displacement and strain measurement: A review.” Meas. Sci. Technol. 20 (6): 062001. https://doi.org/10.1088/0957-0233/20/6/062001.
Pan, B., and H. Xie. 2007. “Full-field strain measurement based on least-square fitting of local displacement for digital image correlation method.” Acta Optica Sin. 27 (11): 1980–1986. https://doi.org/10.3321/j.issn:0253-2239.2007.11.012.
Pan, J., S. Zhang, Z. Su, S. Wu, and D. Zhang. 2021. “Measuring three-dimensional deformation of underwater propellers based on digital image correlation.” Acta Optica Sin. 41 (12): 108–116. https://doi.org/10.3788/AOS202141.1212001.
Peters, W. H., and W. F. Ranson. 1982. “Digital imaging techniques in experimental stress analysis.” Opt. Eng. 21 (3): 427–431. https://doi.org/10.1117/12.7972925.
Poggi, M., F. Tosi, K. Batsos, P. Mordohai, and S. Mattoccia. 2021. “On the synergies between machine learning and binocular stereo for depth estimation from images: A survey.” IEEE Trans. Pattern Anal. Mach. Intell. 44 (9): 5314–5334. https://doi.org/10.1109/TPAMI.2021.3070917.
Potenza, F., C. Rinaldi, E. Ottaviano, and V. Gattulli. 2020. “A robotics and computer-aided procedure for defect evaluation in bridge inspection.” J. Civ. Struct. Health Monit. 10: 471–484. https://doi.org/10.1007/s13349-020-00395-3.
Pushpakumara, B. H. J., and G. A. Thusitha. 2021. “Development of a structural health monitoring tool for underwater concrete structures.” J. Constr. Eng. Manage. 147 (10): 04021135. https://doi.org/10.1061/(ASCE)CO.1943-7862.0002163.
Qin, X., Z. Zhang, C. Huang, M. Dehghan, O. R. Zaiane, and M. Jagersand. 2020. “U2-Net: Going deeper with nested U-structure for salient object detection.” Pattern Recognit. 106: 107404. https://doi.org/10.1016/j.patcog.2020.107404.
Ronneberger, O., P. Fischer, and T. Brox. 2015. “U-Net: Convolutional networks for biomedical image segmentation.” In Proc., Int. Conf. on Medical Image Computing and Computer-Assisted Intervention, 234–241. Berlin, Germany: Springer.
Shao, X., X. Dai, Z. Chen, Y. Dai, S. Dong, and X. He. 2016. “Calibration of stereo-digital image correlation for deformation measurement of large engineering components.” Meas. Sci. Technol. 27 (12): 125010. https://doi.org/10.1088/0957-0233/27/12/125010.
Song, J., A. Liu, H. Zhou, J. Fu, and J. Mao. 2023. “Applications of ROV for underwater inspection of bridge structures and review of its anti-current technologies.” World Sci. Technol. Res. Dev. 45 (3): 365–382. https://doi.org/10.16507/j.issn.1006-6055.2022.10.006.
Sun, W., S. Hou, J. Fan, G. Wu, and F. Ma. 2023. “Ultrasonic computed tomography-based internal-defect detection and location of underwater concrete piers.” Smart Mater. Struct. 32 (12): 125021. https://doi.org/10.1088/1361-665X/ad0c00.
Sutton, M. A., J. J. Orteu, and H. Schreier. 2009. Image correlation for shape, motion and deformation measurements: Basic concepts, theory and applications. Berlin: Springer.
Teng, S., et al. 2024. “Review of intelligent detection and health assessment of underwater structures.” Eng. Struct. 308: 117958. https://doi.org/10.1016/j.engstruct.2024.117958.
Wang, S., X. Wu, Y. H. Zhang, and Q. Chen. 2018. “Image crack detection with fully convolutional network based on deep learning.” J. Comput.-Aided Comput. Graphics 30 (5): 859–867. https://doi.org/10.3724/SP.J.1089.2018.16573.
Wu, T., S. Hou, W. Sun, J. Shi, F. Yang, J. Zhang, G. Wu, and X. He. 2023. “Visual measurement method for three-dimensional shape of underwater bridge piers considering multirefraction correction.” Autom. Constr. 146: 104706. https://doi.org/10.1016/j.autcon.2022.104706.
Yamaguchi, I. 1981. “Speckle displacement and decorrelation in the diffraction and image fields for small object deformation.” Optica Acta Int. J. Opt. 28 (10): 1359–1376. https://doi.org/10.1080/713820454.
Zhang, K. W., J. Liang, W. You, and M. D. Ren. 2016. “Fast morphology measurement based on the binocular vision and speckle projection.” Laser Infrared 46 (12): 1517–1520. https://doi.org/10.3969/j.issn.1001-5078.2016.12.016.
Zhang, X., T. Wang, J. Qi, H. Lu, and G. Wang. 2018. “Progressive attention guided recurrent network for salient object detection.” In Proc., Institute of Electrical and Electronics Engineers Conf. on Computer Vision and Pattern Recognition, 714–722. Piscataway, NJ: IEEE.
Zhu, J., C. Zhang, H. Qi, and Z. Lu. 2020. “Vision-based defects detection for bridges using transfer learning and convolutional neural networks.” Struct. Infrastruct. Eng. 16 (7): 1037–1049. https://doi.org/10.1080/15732479.2019.1680709.
Information & Authors
Information
Published In

Journal of Bridge Engineering
Volume 30 • Issue 1 • January 2025
Copyright
This work is made available under the terms of the Creative Commons Attribution 4.0 International license, https://creativecommons.org/licenses/by/4.0/.
History
Received: May 7, 2024
Accepted: Aug 5, 2024
Published online: Oct 17, 2024
Published in print: Jan 1, 2025
Discussion open until: Mar 17, 2025
Authors
Metrics & Citations
Metrics
Citations
Download citation
If you have the appropriate software installed, you can download article citation data to the citation manager of your choice. Simply select your manager software from the list below and click Download.