Lunar Leap Robot: 3M Architecture–Enhanced Deep Reinforcement Learning Method for Quadruped Robot Jumping in Low-Gravity Environment
Publication: Journal of Aerospace Engineering
Volume 37, Issue 6
Abstract
Legged robots offer advantages such as rapid mobility, adept obstacle-surmounting capabilities, and long mission life in lunar exploration missions. The low-gravity environment on the Moon enhances these benefits, particularly in enabling efficient jumps. However, challenges arise from the complexity of the jumping motion and the difficulty in maintaining stability. This paper introduces an innovative algorithm that integrates deep reinforcement learning with a main point trajectory generator, thus providing a reference for training with minimal reliance on human intuition and prior knowledge. Additionally, fine-grained policy optimization is achieved through a multistage reward structure based on the decomposition of the jumping process. Further, the concept of multitask experience-sharing is proposed to facilitate efficient learning across tasks involving plain terrain jumping and overcoming large obstacles. Simulation results demonstrate the effectiveness of the proposed algorithm in achieving precise and stable jumps, reaching heights approximately five times the robot’s height and distances over five times its body length under lunar gravity. Moreover, the robot exhibits agile strategies, successfully overcoming platforms with a height of 2.5 times its body.
Introduction
Lunar exploration has gained prominence in recent years, necessitating advanced robotics for ground operations and construction missions on the lunar surface. The Moon’s unique conditions, such as a weak gravitational field and lunar dust, present challenges for robot functionality.
Researchers have been focusing on developing more flexible and efficient rovers (Kolvenbach et al. 2019; Haldane et al. 2016), and legged robots stand out for their adaptability to diverse terrains and ability to execute effective jumping actions in a weak gravitational field. Traditional tracked or wheeled rovers maintain a grip on the ground to generate friction for moving forward on a continuous path. They lack traction in low-gravity environments and are susceptible to unstable bouncing upon encountering obstacles, resulting in slow speeds and subpar adaptability to rugged surfaces (Yu et al. 2018). In contrast, legged robots, particularly quadrupeds with various gaits, demonstrate remarkable potential in lunar exploration applications (Qi et al. 2023a).
Yet, controlling the jumping gait is challenging (Zhang et al. 2020; Luo and Luo 2022; Chignoli et al. 2022; Li et al. 2021). The robot propels itself off the ground and enters a contactless underactuated flight phase, which is prolonged under low gravity, and must maintain balance against the significant impulse during the subsequent landing. The switching between different contact configurations poses control challenges, particularly considering the high-dimensional and nonlinear discontinuous dynamics of quadruped robots (Li et al. 2023b; Qi et al. 2023b; Roscia et al. 2023).
Traditional quadruped motion control algorithms typically simplify the nonlinear control problem into a linear one to circumvent complex nonlinear differential equations. Common control methods include virtual model control (Gehring et al. 2013; Ajallooeian et al. 2013a, b), model predictive control (Li et al. 2023a; Villarreal et al. 2020; Ding et al. 2021), and whole-body control (Katayama and Ohtsuka 2022), which tackle optimization problems through quadratic programming and adjust various feedback parameters to track the planned motion trajectories correctly. However, these methods require complex modeling and derivation of dynamics (Manchester and Kuindersma 2017) as well as much expertise and tedious manual adjustments (Tan et al. 2018). Stable jumping actions were achieved by combining trajectory optimization and high-frequency tracking controllers (Nguyen et al. 2019). A scheme for motion planning and control of jumping is developed based on tractable quadratic programming (Chen et al. 2020). However, these approaches only address fixed tasks based on customized programs. For complex tasks where optimal behavior does not follow predetermined patterns, traditional control methods struggle to achieve high performance (Zhu et al. 2019).
Reinforcement learning (RL) methods do not require accurate dynamics to model the motion process (Aractingi et al. 2023a, b; Sang and Wang 2022; Ji et al. 2019). To utilize these methods, individuals implicitly guide the learning of model parameters through the reward function, eliminating the need for manual tuning (Haarnoja et al. 2018b). Jumping on an asteroid was achieved by using end-to-end multiagent reinforcement learning. These methods demonstrate robustness and adaptability to external disturbances and unknown environments (Ji et al. 2022; Nahrendra et al. 2023). However, end-to-end RL encompasses a large search space. Especially for tasks with complex actions like jumping in low gravity, learning entirely from scratch does not yield effective strategies (Bussola et al. 2023) but rather results in unnatural and unstable locomotion. To address this issue, it is necessary to develop specific algorithms based on RL.
Several studies have explored hybrid methods, which integrate traditional methods with RL (Li et al. 2023b; Lee et al. 2020; Bellegarda and Ijspeert 2022; Pinosky et al. 2023; Baek et al. 2022; Johannink et al. 2019; Rana et al. 2023; Shi et al. 2022; Srouji et al. 2018; Iscen et al. 2018). A notable hybrid approach is the residual RL framework, which aims to learn corrective residual strategies to enhance control priors (Rana et al. 2023). It divides control problems into two parts: a part that can be effectively solved by conventional feedback control methods; and a part that can be solved by RL. The final control strategy is a superposition of the two control signals (Johannink et al. 2019). A structured control network is proposed (Srouji et al. 2018), partitioning a general multilayer perceptron (MLP) into two submodules: nonlinear control for forward and global control; and linear control for stabilizing local dynamics around global control residuals. A method that combines a learned predictive model with a state-action policy network based on empirical data (Pinosky et al. 2023) is developed to enhance the learning ability of robotic systems. A hybrid of learning and model-based control is proposed (Baek et al. 2022), combining an optimal controller and integrated deep reinforcement learning soft actor-critic (SAC). Moreover, RL is employed to track the optimal trajectory of a simplified sagittal plane model based on the dynamic model (Li et al. 2023b). These hybrid methods mitigate the shortcomings of traditional methods regarding strategy robustness and flexibility but still require extensive design work for the traditional controller based on dynamics.
A method that combines central pattern generators (CPG) with deep reinforcement learning (DRL) is proposed (Bellegarda and Ijspeert 2022), where the agent directly adjusts the set values (amplitude and frequency) of intrinsic oscillators and coordinates the rhythmic behavior among different oscillators to achieve weight-bearing locomotion. The policies modulating trajectory generator (PMTG) architecture (Iscen et al. 2018) is used to provide prior-generated knowledge of locomotion-related gait parameters in the form of parameterized trajectory generators for learning, enabling robust walking of quadruped robots in complex terrains (Lee et al. 2020). Prior foot trajectories of different locomotion tasks are optimized using evolutionary algorithms, with RL enhancing the generated residual signals (Shi et al. 2022). These hybrid methods employ more intuitive and simpler prior information and have achieved good results in various application tasks. However, there is a lack of attempts to control unstable low-gravity jumping gait with these hybrid methods.
In our previous attempts with prior foot trajectory and existing hybrid methods, we have found that uniformly sparse sampling throughout the entire jumping cycle is not the most effective approach. Since each stage of the jump has a different impact on performance, the trajectory needs to retain its simplicity of design while focusing on guiding effectiveness with emphasis. This paper introduces a novel hybrid algorithm that combines DRL with the main point trajectory generator (MPTG), aiming to maximize the use of the prior trajectory while minimizing reliance on human intuition. Simulation experiments of jumping under lunar gravity validate its effectiveness.
The three major contributions of this paper are: (1) the introduction of the MPTG for low-gravity jumping tasks, which eliminates the need for complex dynamics and minimizes dependence on intuitive human priors. MPTG concentrates on critical moments pivotal to task success, provides effective priors for DRL, and directs the agent toward the right training path for optimal actions. (2) A hierarchical multistage reward of DRL is designed to generate compensatory optimal strategies. The jumping task is systematically decomposed into four stages; each stage is assigned specific objectives at various levels, resulting in a more controllable optimization process. (3) A multitask experience-sharing framework is proposed, allowing different tasks to share transition data with the same replay buffer during training, enhancing generalization abilities and facilitating sample efficiency for each task.
Preliminaries
A quadruped motion controller driven by learning can be formulated as a Markov decision process denoted by a tuple (, , , , ), where represents the set of all possible states, represents the set of actions, constitutes the probability transition function, denotes the reward, and indicates the initial state distribution. At each time step , the controller furnishes a control signal , grounded in the current state . Then, the robot then follows the provided control signal, leading to a reward . The subsequent state is contingent on the state transition function.
The SAC (Haarnoja et al. 2018c) is the choice for this study because of its superior performance in robotic continuous control tasks compared with alternatives such as proximal policy optimization (PPO), trust region policy optimization (TRPO), and TD3 (Haarnoja et al. 2018a). SAC merges the advantages of stochastic policy frameworks with off-policy learning and introduces the maximum entropy model, allowing for a broader exploration of action spaces while maintaining high sample efficiency.
The SAC algorithm is designed based on the actor-critic network framework and consists of an actor network and four critic networks. The four critic networks include critic and target critic networks of value estimation, critic, and critic networks of action-state value estimation.
The goal of the controller learned based on the SAC algorithm is to find an optimal controller that maximizes the weighted objective of rewards and the policy entropywhere = the coefficient of the entropy reward and represents the importance of the entropy. The calculation formula for the entropy is defined as
(1)
(2)
Transition (, , , ) is extracted from the experience replay buffer to update network parameters. The loss function for updating the parameters of the critic and critic networks iswhere = the true value estimate of state based on the optimal Bellman equationwhere = the predicted value estimate of the state based on the actual action; = the experience replay buffer; and the loss is a mean square error loss, where a batch of data is taken from the replay buffer to calculate the average. The loss function for the update of the critic network iswhere = the true value output by the critic network and is the value estimate of the state, including the following entropy term:
(3)
(4)
(5)
(6)
The loss function for updating the actor network iswhere = the action predicted by the actor network.
(7)
Methodology
This section introduces a novel quadruped jumping method, named 3M-DRL, which stands for main point trajectory generator, multistage reward, and multitask experience-sharing deep reinforcement learning. The overall controller architecture is depicted in Fig. 1.
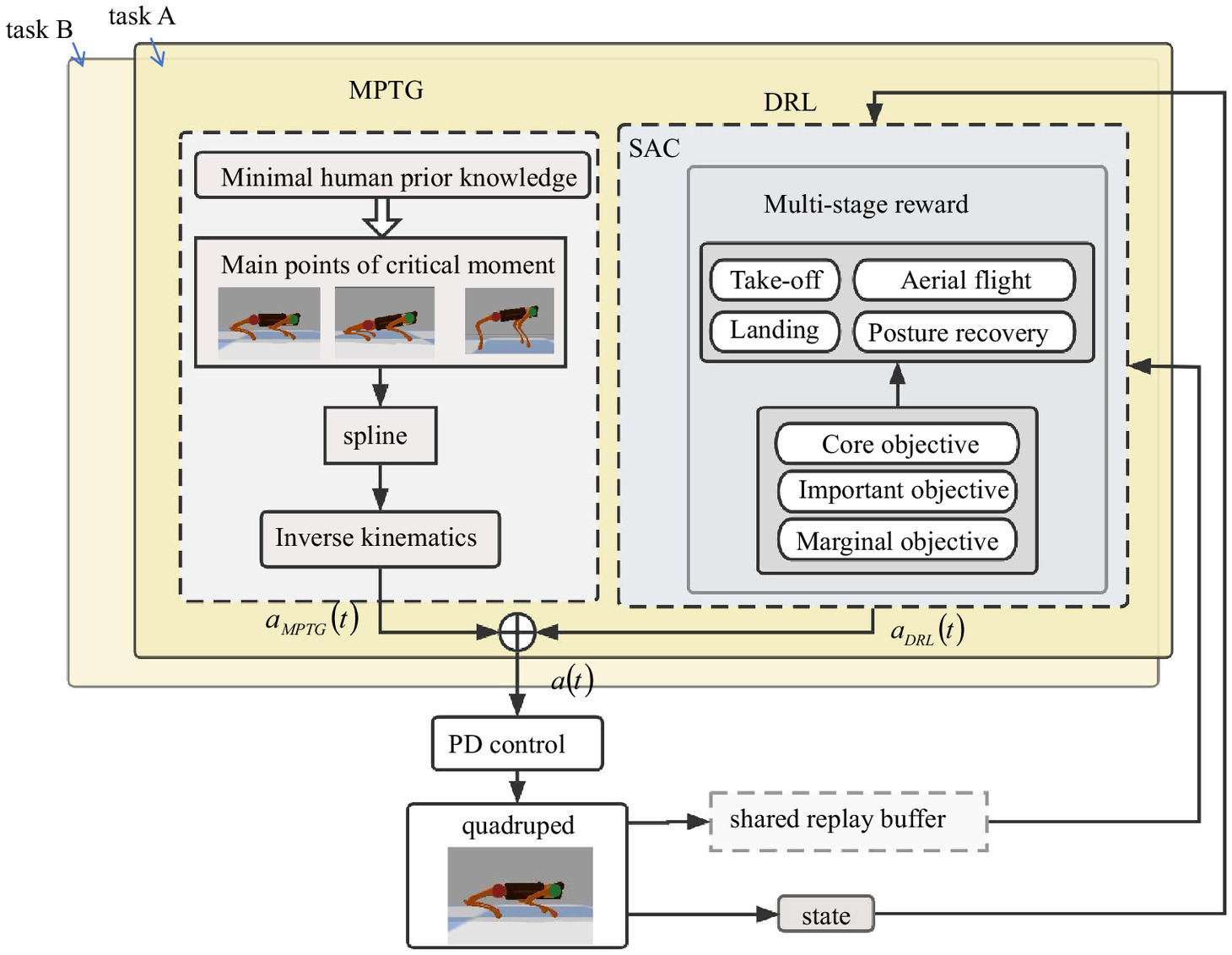
This architecture is divided into high-level planning and low-level tracking components. High-level planning integrates MPTG and DRL to output the robot’s desired joint angle positions at each time step. Initially, MPTG generates prior trajectories based on key jumping actions. Subsequently, DRL develops a compensatory strategy employing a multistage reward system derived from task decomposition. During the DRL training process, various tasks contribute experience data to a shared replay buffer, which is used to update the network parameters. The complete high-level policy output is a vector of the desired angles for all joints, representing coordination strategies for all legs. This output is the sum of the prior trajectories generated by MPTG and the compensatory strategies from DRL, as shown
(8)
Next, the low-level PD tracker implements the calculated torques on the robot, and the current state data are fed back to the DRL for observation. The observed state includes the position, attitude, linear and angular velocity of the robot body, the angle, angular velocity, and torque of each joint as well as Boolean values that indicate the foot-contact state.
Main Points Trajectory Generator
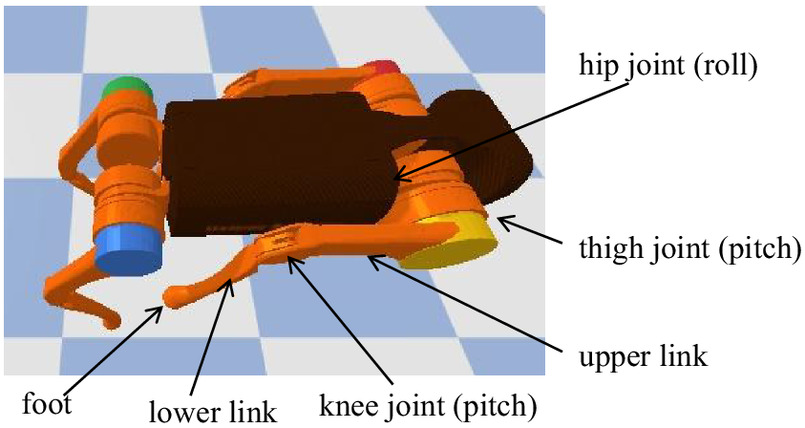
To provide feasible guidance for DRL training, reduce manual design efforts, and minimize the risk of tumbling under low gravity conditions, We employ the MPTG design where all four legs move consistently. The study focuses on the kinematics of a single leg, which includes upper and lower links, along with motors for hip, thigh, and knee joints following a roll-pitch-pitch scheme (Fig. 2). The analysis primarily addresses the forward and vertical movements, which form a 2D plane in the coordinate system of the thigh joint (Fig. 3).
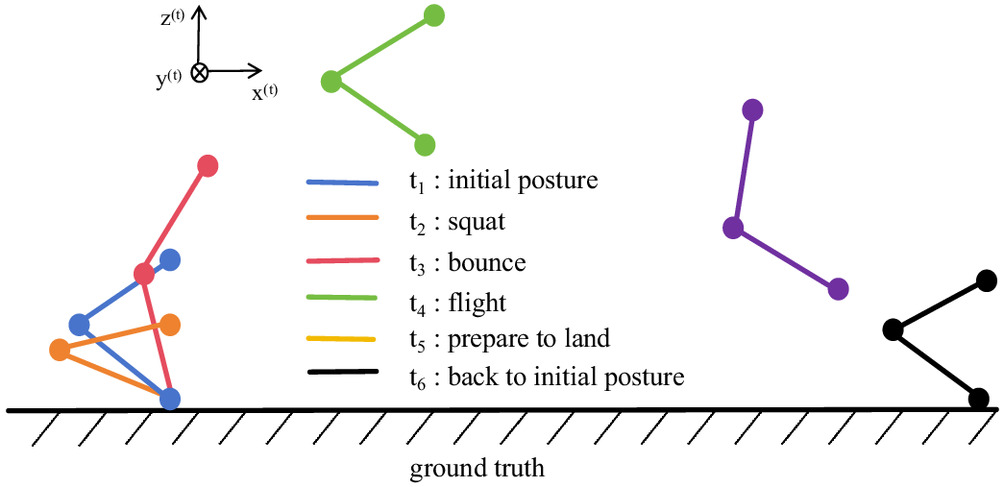
Drawing on previous work (Shi et al. 2022) and deconstructing the jumping process, we have identified several essential actions. As demonstrated in Fig. 3, these actions can be sufficiently and comprehensively represented by six main points. The takeoff action requires rapid acceleration over a brief period to achieve maximum velocity before leaving the ground. This incorporates the stretch-shortening cycle mechanism found in nature and necessitates three main points to simulate the quick transition from the initial posture to the lowest squat and then to the bounce. Additionally, three more main points are needed to guide the leg during flight, prepare to land, and back to the initial posture.
The foot-end trajectory includes the foot’s positional coordinates of these actions relative to the thigh joint coordinate system and their corresponding time points within the jumping sequence. After completing the foot-end trajectory design, denoted as , in which represents the th main point, it is then interpolated by a spline to generate the complete foot trajectory , in which represents the th interpolation point. Subsequently, through inverse kinematics, the trajectory is transformed into a joint angle trajectory , serving as the benchmark for DRL. Fig. 4 illustrates the schematic diagram for solving the inverse kinematics of a single leg, defining the rotation angles of the three joints as , , and . The superscript denotes the hip joint coordinate system, and denotes the thigh coordinate system. In our simplified planar problem, where the hip joint coordinate system is parallel to the body coordinate system (), the inverse kinematics are simplified to solve the values of joint angles (, ) at each time step by referring to the known coordinate position of the foot
(9)
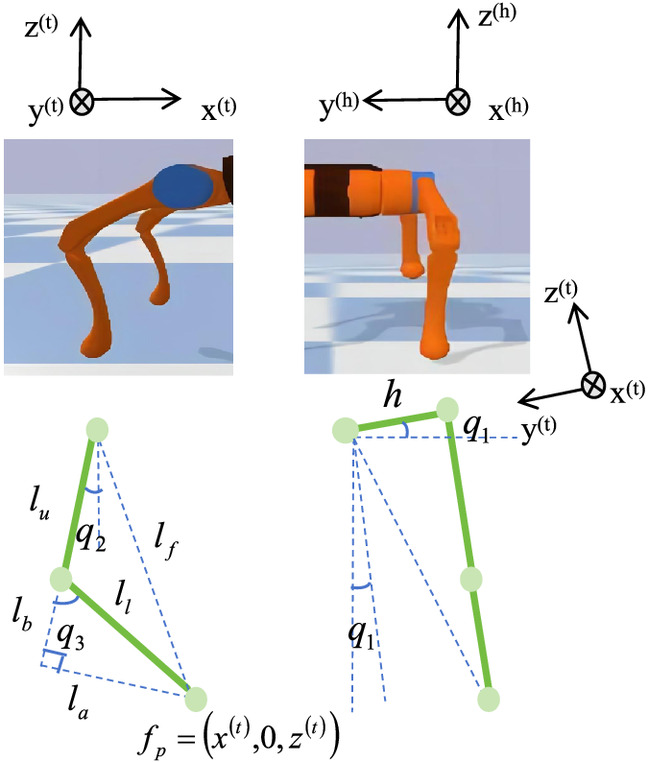
Meanwhile, the following geometric relationships exist:where = the length of the upper link; = the length of the lower link; and can be solved by Eqs. (10) and (11)
(10)
(11)
(12)
The values of and can be calculated as follows:
(13)
(14)
The specific steps of MPTG are presented in Algorithm 1.
| Input: , the position of the foot at main points and their corresponding time points; , number of interpolation control points; , interpolation time interval, equal to the duration of one cycle divided by ; , the number of columns in : |
| 1. Initialize an empty interpolation control point list: |
| 2. obtain the time series from |
| 3. generate a time series with time intervals incrementing by |
| 4. for each in do |
| 5. |
| 6. append into |
| 7. end for |
| 8. Initialize an empty joint angle trajectory list: |
| 9. extract the foot position from |
| 10. for each in do |
| 11. joint_angle [] = inverse_kinematics () |
| 12. [with Eqs. (9)–(14)] |
| 13. append , joint_angle [] into |
| 14. end for |
| Output: the joint angle trajectory , |
Multistage Reward
To address the challenge that generic sparse reward fails to evaluate intermediate actions during intricate jumping progress and leads to convergence issues, this study employs a multistage reward strategy based on task decomposition.
The jumping process is divided into takeoff, aerial flight, landing, and posture recovery stages based on their distinct control requirements. The border between takeoff and aerial flight is identified when foot-end force sensors all register zero and this state lasts for more than 0.1 s. The landing stage starts when the robot reaches peak height, and the posture recovery starts when the robot’s descent speed is reduced to zero and this state lasts for more than 0.1 s. Within each stage, rewards are categorized into core, important, and marginal objectives with a weight ratio decreased in sequence to balance various coupled reward items and prevent overoptimization of inappropriate indicators.
This framework is described in Eqs. (15) and (16), where the agent receives a reward at each time step as a weighted sum of different componentswhere ranges from 1 to 4, representing the th stage.
(15)
(16)
The following exponential decay function is given to describe a reward term where the expectation approaches zero:where = the scaling coefficient. When represents the difference between two vectors, this formula expects the two vectors to be as close as possible. Reward items and the corresponding weight coefficients in each stage are listed in Table 1.
(17)
| Stage | ||||||
|---|---|---|---|---|---|---|
| Takeoff | 5 | 2 | 0.1 | if nontactile contact point | ||
| Aerial flight | 5 | 3 | 1 | if nontactile contact point | ||
| Landing | 7.5 | 3 | 1 | if nontactile contact point | 0 | |
| Posture recovery | 5 | 2 | 1 | if nontactile contact point |
The first stage is the takeoff. The core objective is to maximize vertical and forward speed to facilitate powerful jumping movements. The important objective is to minimize falls by imposing a significant penalty () when the nontactile contact is TRUE. In PyBullet (Coumans and Bai 2016), nontactile contact is detected if the robot has more than one nonfoot contact point. The marginal objective as is to encourage the maintenance of body angle to assist stability.
The second stage is the aerial flight. The core objective is to maintain stability and prevent flips by penalizing deviations from the initial posture using the exponential decay function. The important objective is to avoid interference from leg shaking on the stability of the robot body. The marginal objective is to assist in maintaining body stability through a significant penalty () for falling.
The third stage is the landing. The core objective is to avoid falling through a significant penalty (). The important objective is to maintain body stability by encouraging alignment with the initial posture. The marginal objective is set to zero to maintain simplicity in design since the first two items encompass all requirements.
The last stage is the posture recovery. The core objective is to facilitate a rapid return to stable posture by encouraging minimizing the deviation from initial joint angles. The important objective is to avoid imbalance led by improper recovery actions through a significant penalty () for falling. The marginal objective is to prevent instability caused by abrupt changes by controlling the rate of change in body angle.
The weight coefficients in Table 1 were determined through grid search experiments. Initial magnitudes of weight coefficients for core, important, and marginal objectives were provided based on tuning experience, with search ranges set as [2.5, 5, 7.5, 10], [1, 2, 3, 4], and [0.1, 1, 1.5], respectively. The optimal parameter combinations for each stage were selected from permutations within the search ranges.
This reward mechanism enables more controllable optimization through precise stage-specific objective definitions, increases training efficiency without being overwhelmed by the complexity of the entire task, and enhances adaptability by allowing the agent to adjust to varying requirements and environmental changes through task decomposition.
Under this reward mechanism, the study employs the SAC algorithm to train the DRL part. The employed neural network structure comprises an MLP with two hidden layers, each consisting of 256 neurons with ReLU activation.
Experience Sharing
To enhance the efficiency of data utilization and generalization ability, this study employs a multitask experience-sharing approach, thereby optimizing the neural network policies of different tasks separately and alternately while sharing the interaction transition data (, , , ).
The training framework is presented in Fig. 5, where each task operates with its dedicated policy network, and the network parameters are updated by randomly sampling data from the shared replay buffer. The approach employs a task-switching mechanism to alternate between different tasks based on a predesignated number of design episodes, determining the current task undergoing interactive training. In traditional offline DRL training, each task independently generates interaction data to train its corresponding models, resulting in inefficient data resource utilization and model redundancy. In the experience-sharing approach, interaction data from multiple tasks is consolidated into a shared replay buffer, enhancing task performance by leveraging existing interaction data resources and introducing data augmentation. Given potential correlations between tasks, the model can extract additional information from samples of other tasks, facilitating knowledge transfer and performance improvement. During network parameter optimization for a specific task, the network parameters of other tasks remain frozen.
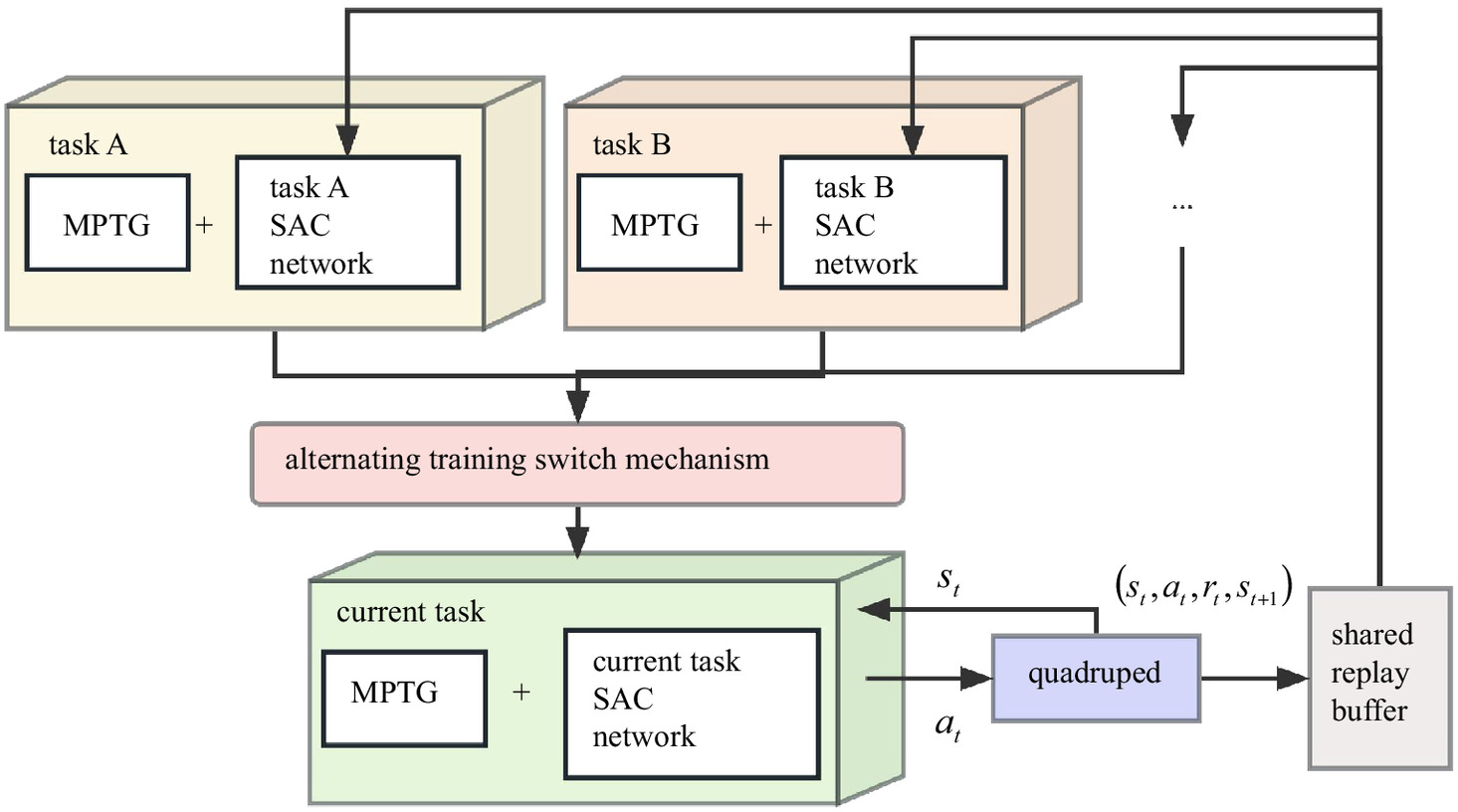
The complete steps of the proposed 3M-DRL are detailed in Algorithm 2.
| Input: E, maximum training step for DRL in each iteration; , Gaussian noise for exploration; R, number of training episodes in each alternation: |
| 1. Initialize actor networks, critic networks, and target networks for each task |
| 2. Initialize a shared experience pool B |
| 3. while not converged do |
| 4. /* Set a counter to record training episodes */ |
| 5. training_counter = 0 |
| 6. /* switch to the next task every R episodes */ |
| 7. if training_counter% then |
| 8. env_index = (training_counter// R) % len(env) |
| 9. set_env(env[env_index]) |
| 10. end if |
| 11. while not reach maximum training Step E do |
| 12. /* MPTG strategy */ |
| 13. joint angle trajectory with Algorithm 3.1 |
| 14. /* DRL strategy */ |
| 15. = network.select_action(state) |
| 16. residual control signal: |
| 17. /* final strategy */ |
| 18. |
| 19. execute in the current task environment |
| 20. state = next state |
| 21. episode_reward + = reward |
| 22. append the transition (, , , ) into |
| 23. /* sample a batch of data from B to update network parameters */ |
| 24. update Q critic network with Eq. (3) |
| 25. update V critic network with Eq. (5) |
| 26. update actor network with Eq. (7) |
| 27. update target networks through soft updates |
| 28. save parameter data to the current task model |
| 29. end while |
| 30. training_counter + = 1 |
| 31. end while |
Simulation Experiments
This section utilized the simulation engine Pybullet (Coumans and Bai 2016) to test the performance of our algorithm. The gravitational coefficient of the lunar surface is set as . The official URDF file of the Unitree A1 Robot was imported to establish the quadruped model for the simulations. The hardware configuration includes the NVIDIA RTX A4000 GPU with a video memory capacity of 16,183 MB and two Intel(R) Xeon(R) Silver 4210R CPUs.
The simulation results of 3M-DRL are presented in comparison with the baseline SAC across two jumping tasks under lunar gravity. The tasks involve continuous periodic jumping on a plane terrain and leaping over a platform with a height of 1 m. Subsequently, MPTG, multistage reward, and experience-sharing are removed separately from 3M-DRL, generating three variants to verify the individual effectiveness of the three innovative modules.
The metrics for measuring the jumps in the plane terrain jumping task include the maximum jump height/distance, which reflects the ultimate jumping capability, and the distribution of the jump height and distance calculated with 20 sets of data of consecutive jumping, which reflects the accuracy of the jumping. In the platform jumping task, it is assessed whether the robot can complete the task through three checkpoints: (1) whether it can successfully land on the platform; (2) jump off the platform; and (3) keep jumping after going back to the ground.
The generic hyperparameter settings for SAC and 3M-DRL are a learning rate of , a discount factor of 0.99, a batch size of 256, and an entropy coefficient of 0.005. In experience-sharing, the shared replay buffer size is ; in normal separate training, the size of the replay buffer is set to . The adaptive moment estimation is adopted as the optimizer for network training.
3M-DRL Result
This section showcases the superior simulation results of 3M-DRL compared with the baseline SAC in the plane terrain jumping and platform jumping tasks. The platform, at a height of 1 m, poses a significant challenge, being 2.5 times the height of the robot’s body. Both tasks underwent training for one million episodes with identical settings.
Plane Terrain Jumping Task
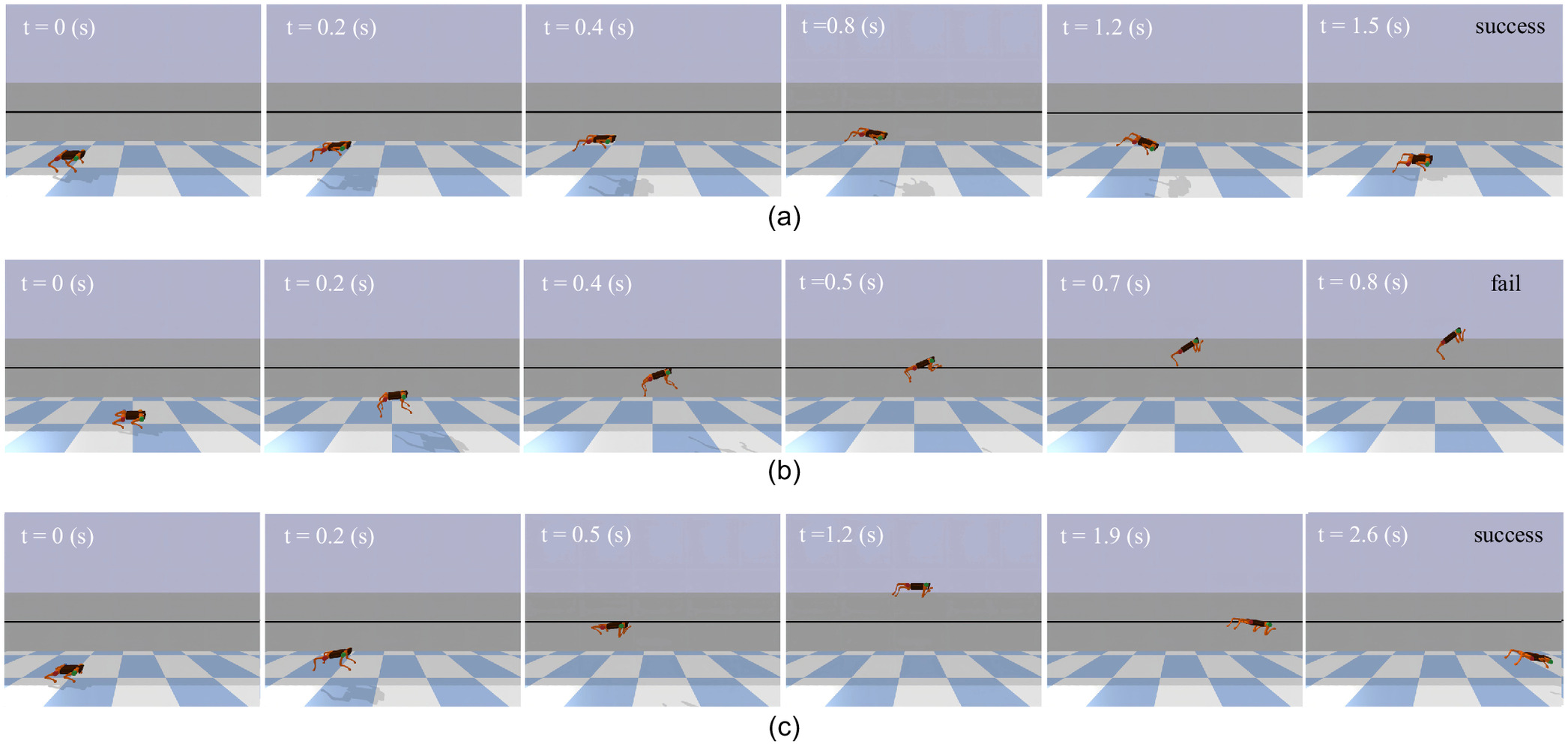
The limitations of the baseline SAC are evident when the robot performs continuous periodic jumping on plane terrain. As illustrated in the snapshots [Fig. 6(b)] and the robot body trajectory (Fig. 7), the robot displays immature jumping postures and insufficient body control. In the lunar environment, where a minor jumping error can send the robot soaring above its body length, these deficiencies are critical. Poor takeoff actions can generate significant rotational torque, causing the robot to spin uncontrollably in the air due to the conservation of angular momentum. Consequently, the robot loses balance and falls, proving that the baseline SAC is unsuitable for the successful completion of the jumping task.
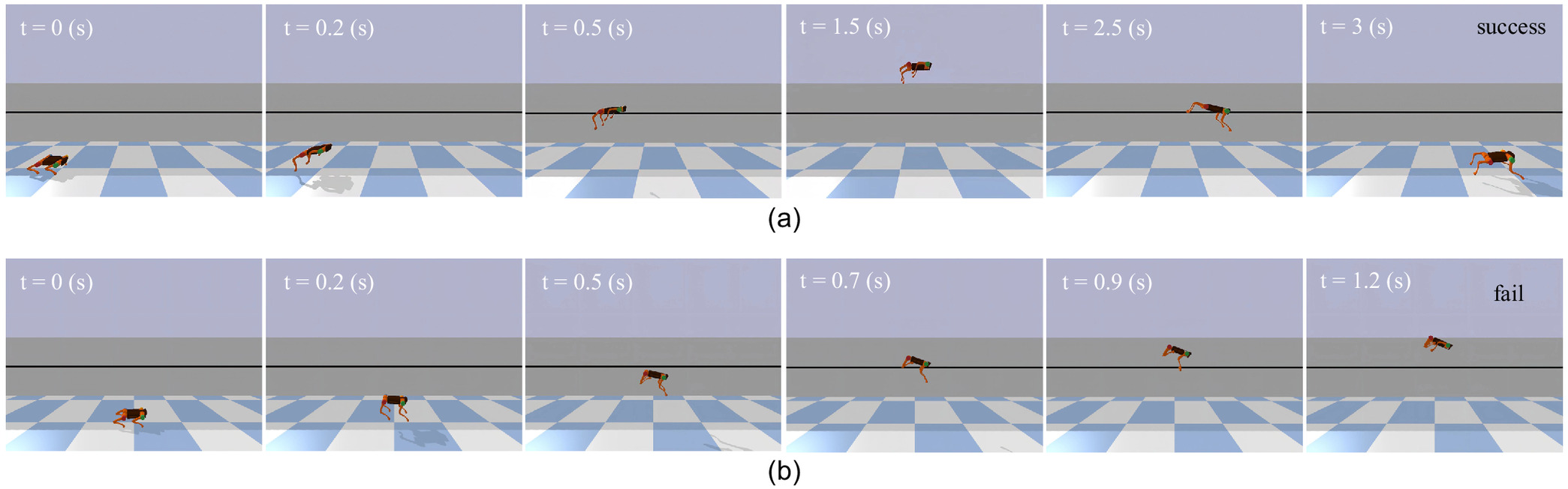
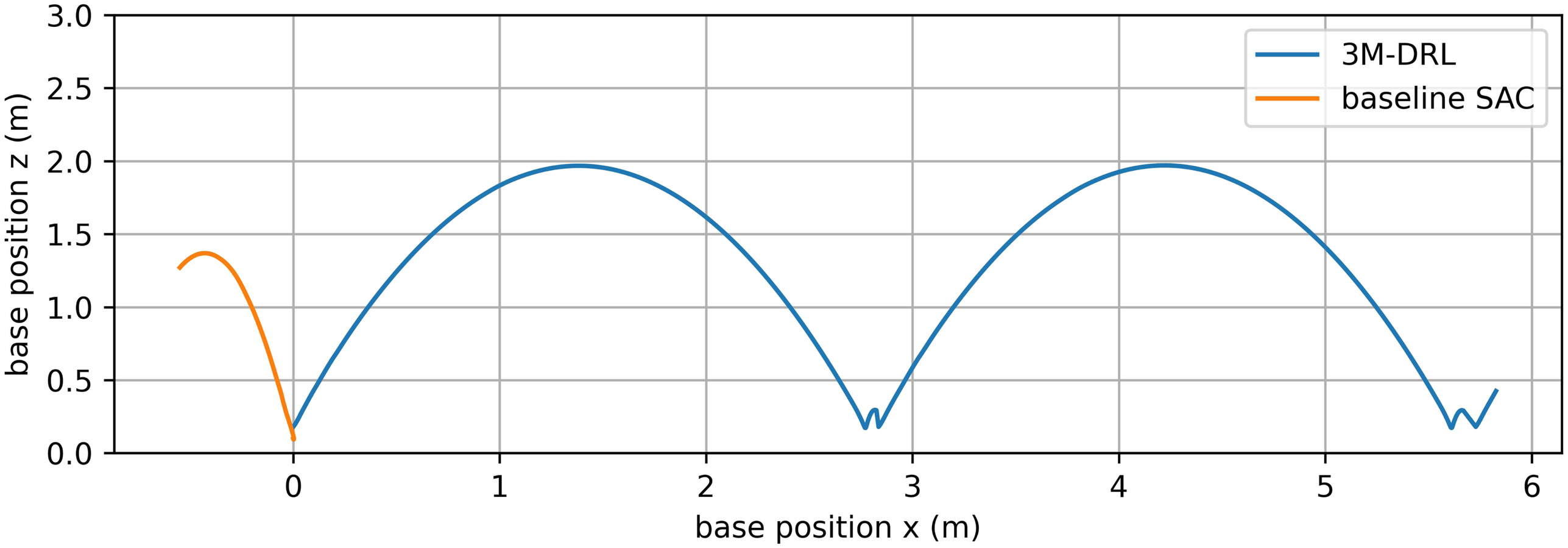
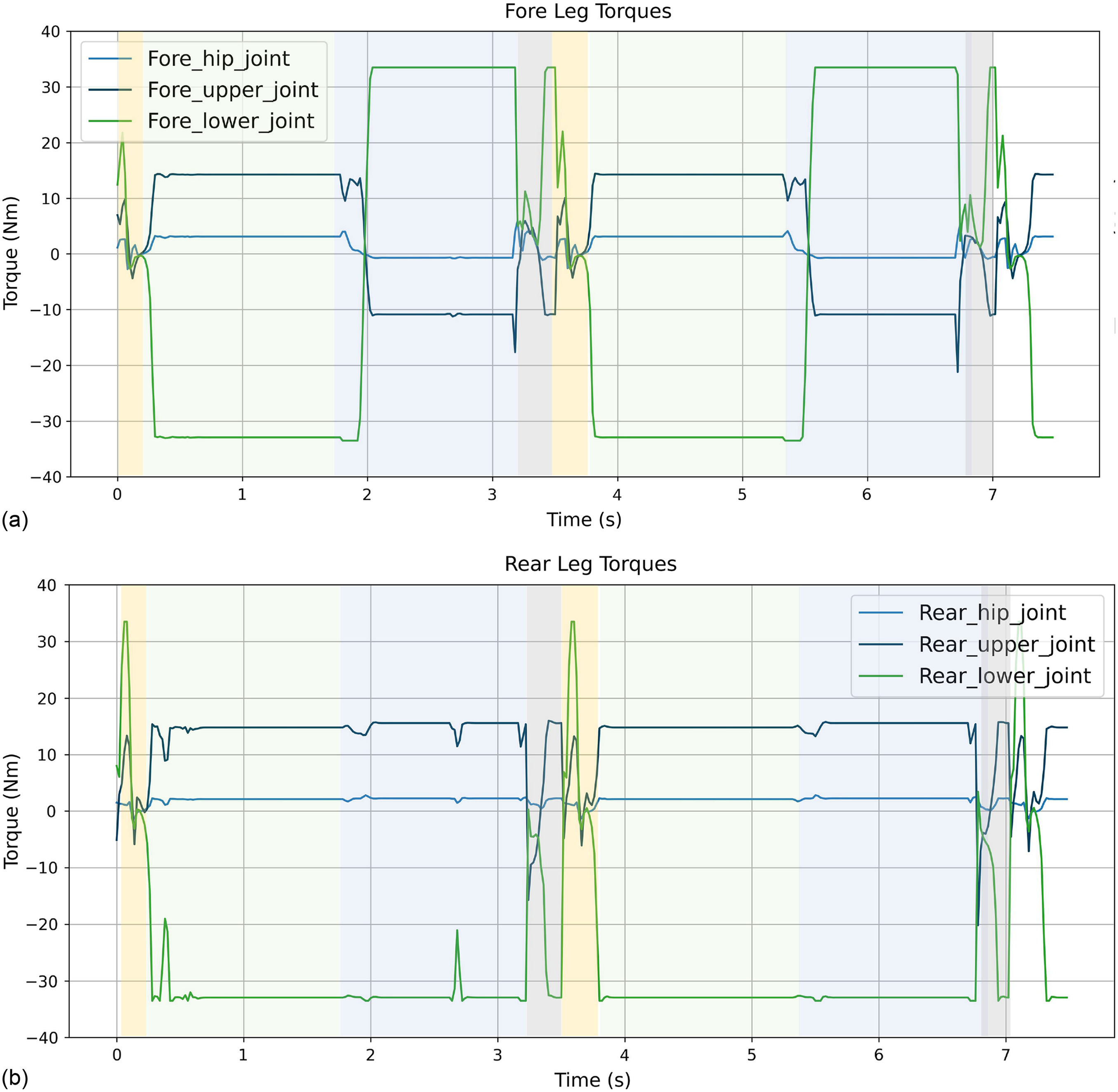
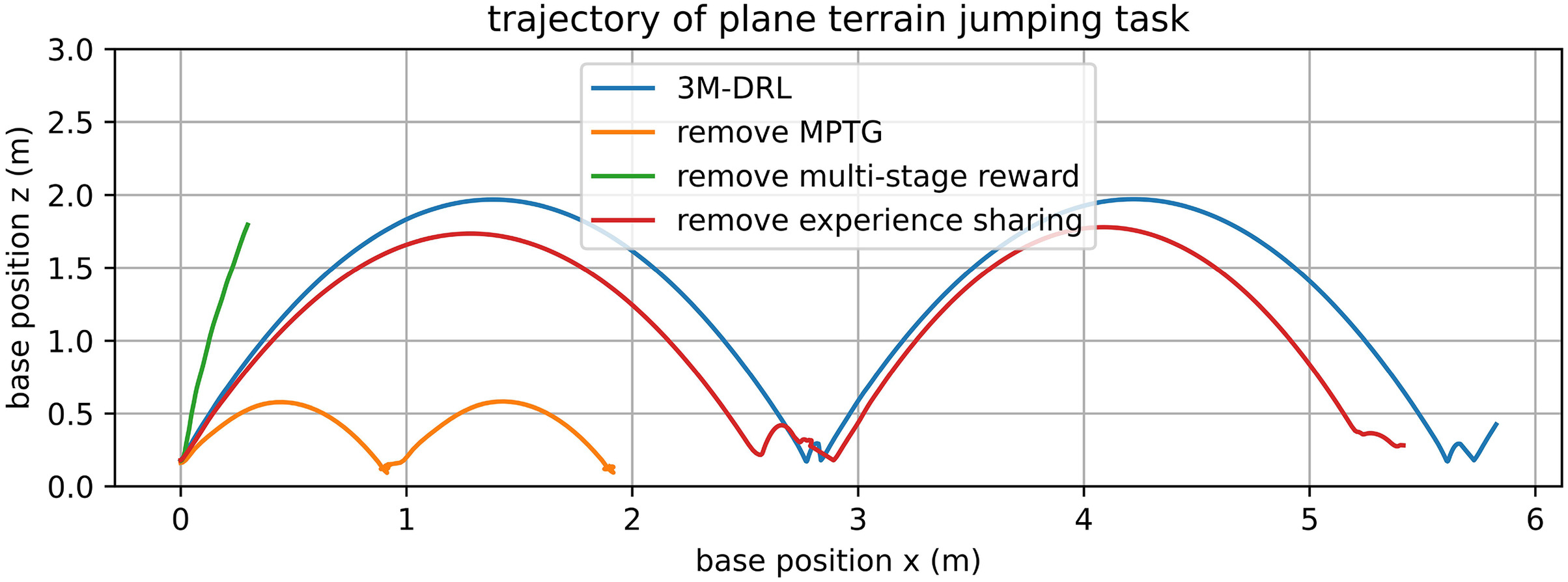
In contrast, the 3M-DRL addresses these deficiencies and significantly improves the robot’s jumping capabilities under low gravity. The snapshots [Fig. 6(a)] and the robot body trajectory (Fig. 7) illustrate the robot’s enhanced performance in continuous periodic jumping. With 3M-DRL, the robot achieves an average jumping height of 2.0012 m and an average jumping distance of 2.7421 m (Table 2). The selected snapshots [Fig. 6(a)] include the moments of initial attitude, take-off, ascent, highest point, descent, and landing, showing a successful jump cycle of the robot. It can be seen that, under the framework of 3M-DRL, the robot learns to tuck its forelimbs like a cat during ascent to improve the jumping performance; during the descent stage, the fore legs open forward, and the rear legs open backward to prepare for a smooth landing. Fig. 8 demonstrates the joint torques of the 3M-DRL algorithm within two jumping cycles, where the yellow zone corresponds to the take-off stage, green to the aerial flight stage, blue to the landing stage, and gray to the posture recovery stage. Following a brief take-off action, the thigh and knee joints continue to output torque stably to maintain balance during the jump, showcasing limb control throughout the entire cycle. The temporal variation of torque in each joint exhibits good regularity and coordination between the fore and rear legs, which is a key factor for the robot’s effective jumping and landing.
| Metric | Statistical type | 3M-DRL | SAC | Remove MPTG | Remove multistage reward | Remove experience sharing |
|---|---|---|---|---|---|---|
| Jumping height (m) | Mean jump height | 2.0012 | — | 0.5867 | — | 1.7381 |
| Standard deviation | 0.0575 | Fail | 0.0566 | Fail | 0.0897 | |
| Variance | 0.0033 | — | 0.0032 | — | 0.0081 | |
| Jumping distance (m) | Mean jump distance | 2.7421 | — | 0.9321 | — | 2.4215 |
| Standard deviation | 0.0705 | Fail | 0.0580 | Fail | 0.1328 | |
| Variance | 0.0049 | 0.0034 | 0.0176 |
Platform Jumping Task
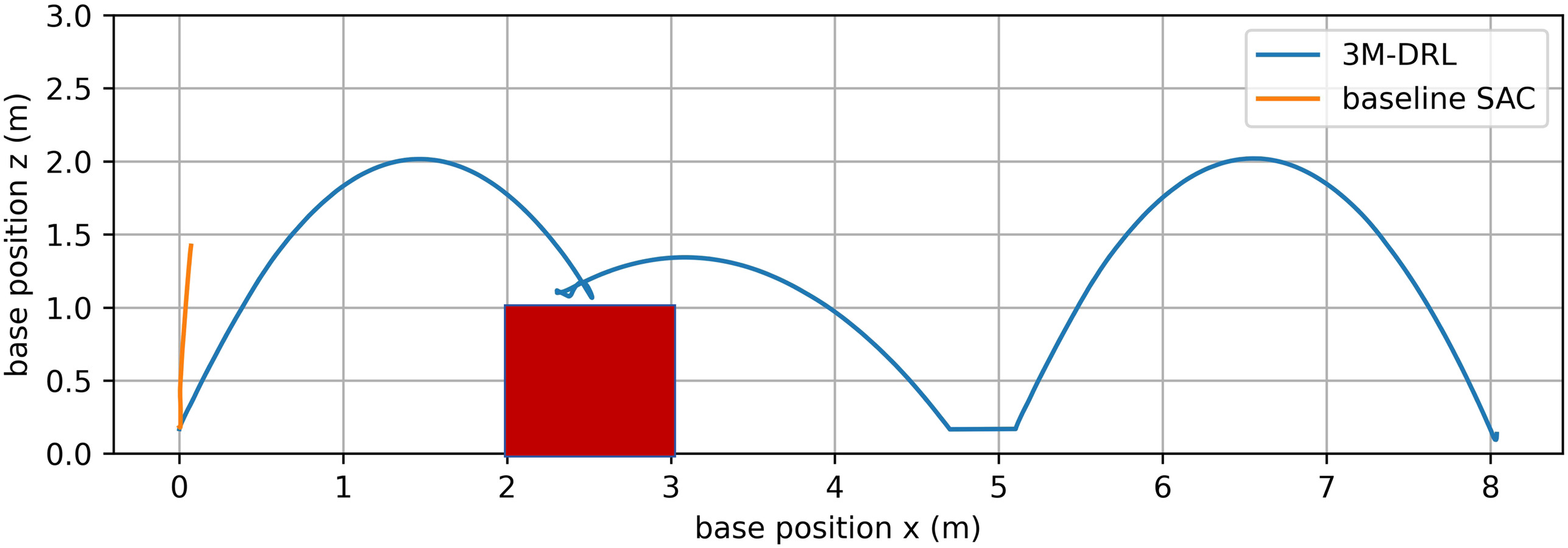
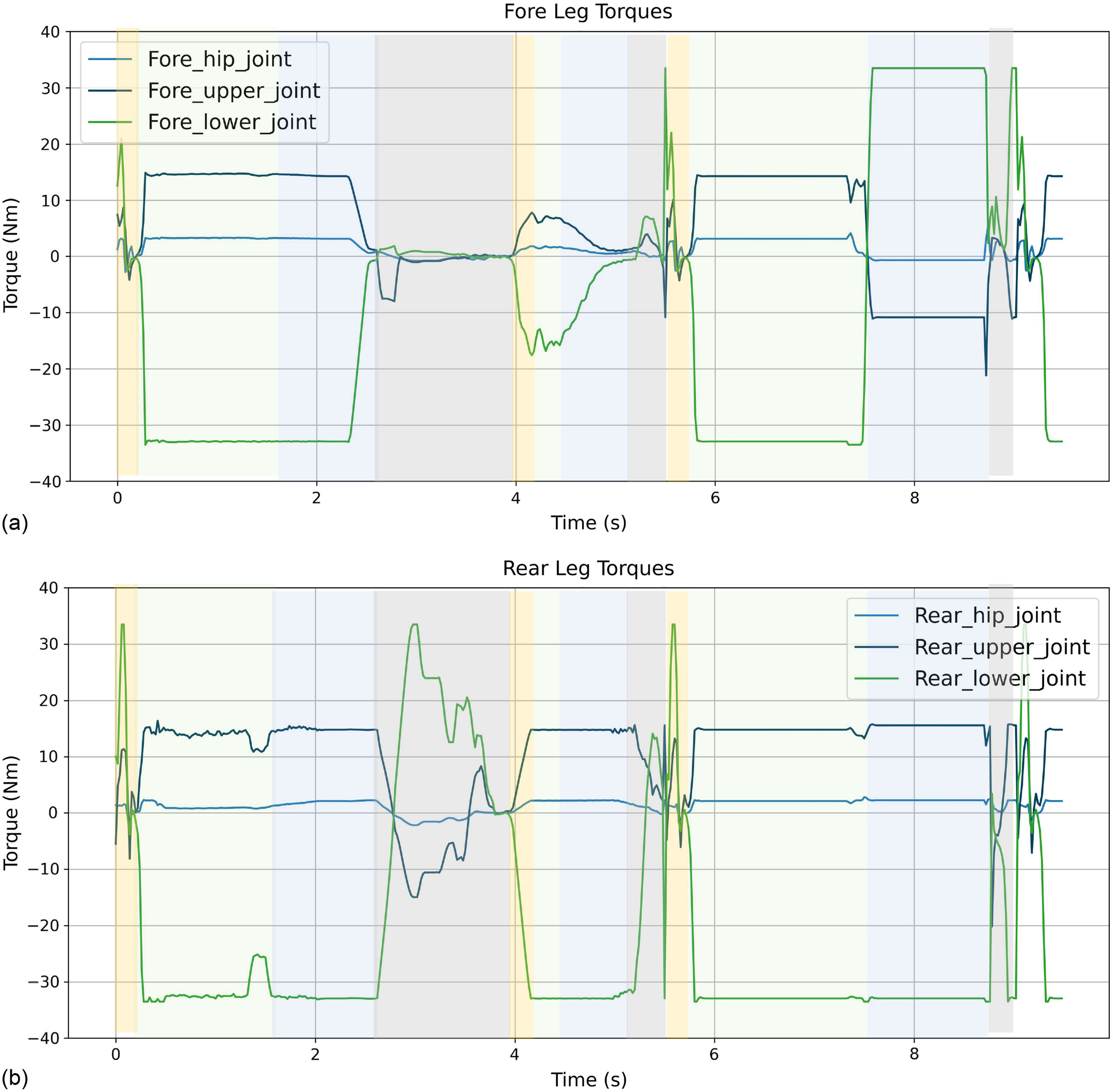
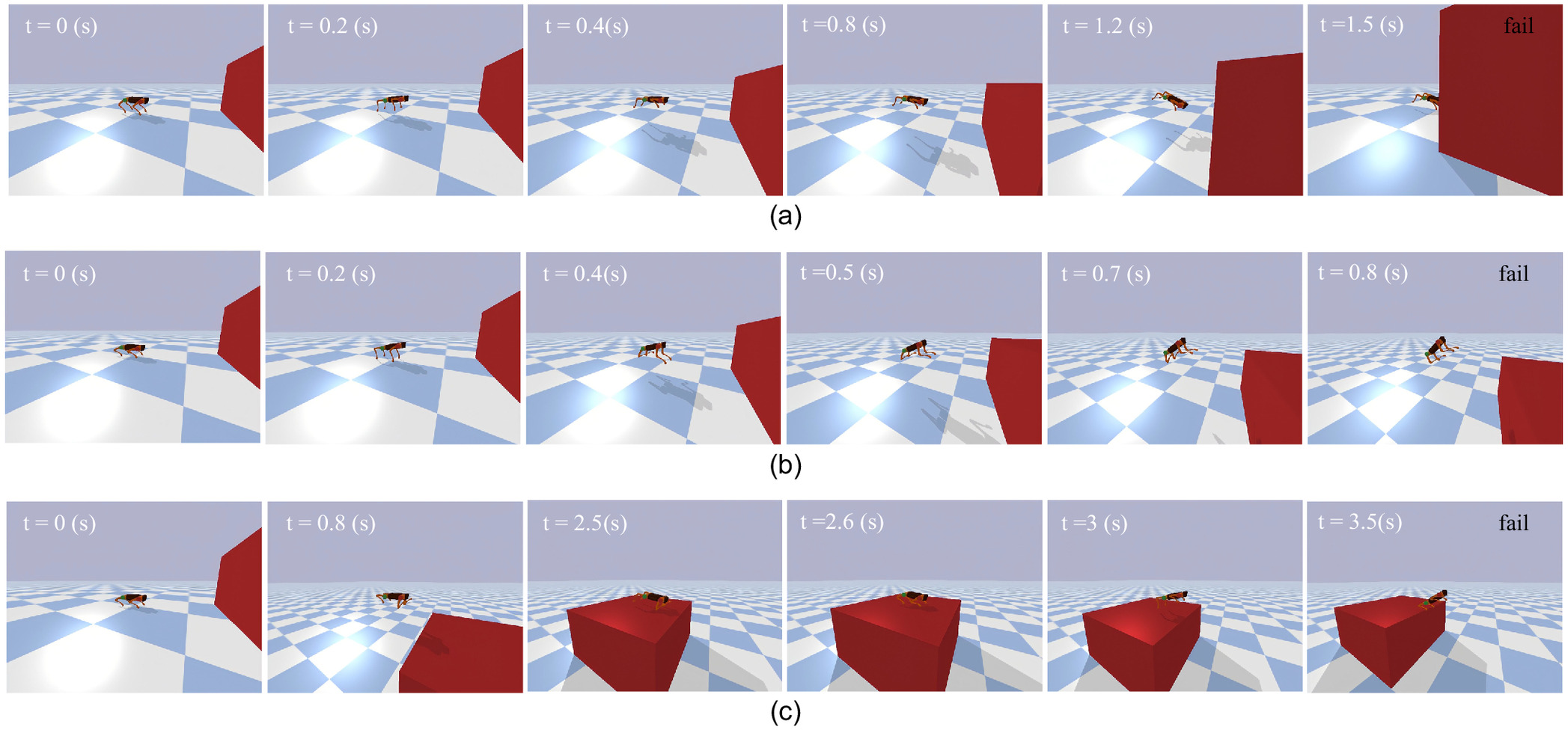
The snapshots [Fig. 9(b)] and the robot body trajectory (Fig. 10) illustrate the failure of the baseline algorithm in the face of the challenging platform jumping task. However, 3M-DRL adeptly trains the robot to overcome this obstacle with strategic flexibility. The snapshots [Fig. 9(a)] capture key moments of the initial posture, ascent, platform landing, platform jumping off, and subsequent ground jump. Fig. 11 displays the joint torques throughout this process. When preparing to land on the platform, the robot retracts its fore legs to avoid collisions, indicated by stable torques. From 2.5 to 4 s, the irregular torque changes of the rear legs are adjustments for posture to prepare for the subsequent jump off the platform. Between 4 and 5 s, the robot adopts a strategy of less foreleg movement, primarily relying on lateral force from the rear legs for a forward jump to ensure stability and minimize impact when jumping off the platform. This strategic reversion signifies the versatility of 3M-DRL, allowing the robot to transition between different objectives and optimize its behavior based on the specific demands of the jumping task.
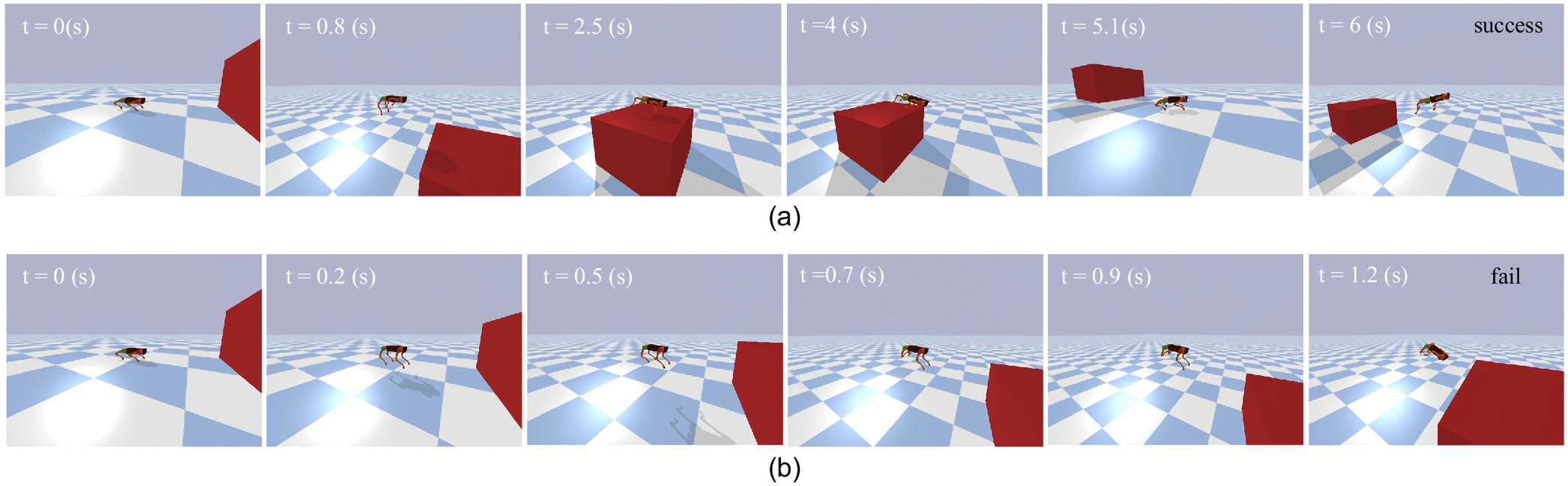
Effect of MPTG
To understand the necessity of MPTG in guiding learning, a variant that removes the MPTG module while retaining identical experimental settings to 3M-DRL is used.
The snapshots [Figs. 12(a) and 14(a)] provide a visual representation of the notable differences in jumping behaviors when MPTG is excluded. MPTG is an essential condition for RL to learn powerful jumping actions, it provides initial feasible solutions, without which RL struggles to learn jumping methods with strong explosive power from scratch. Jump trajectories (Figs. 13 and 15) and quantitative metrics, as summarized in Table 2, further highlight the impact. The inability to receive rewards that encourage high and long jump has resulted in agent leaning toward adopting conservative strategies to optimize stability and obtain stability rewards. Thus, the final result is a significant decrease in jumping height and distance, measuring only 0.293 and 0.34 times the values achieved by 3M-DRL, respectively. The convergence plots of the training process (Fig. 16) show a less effective training process without MPTG.
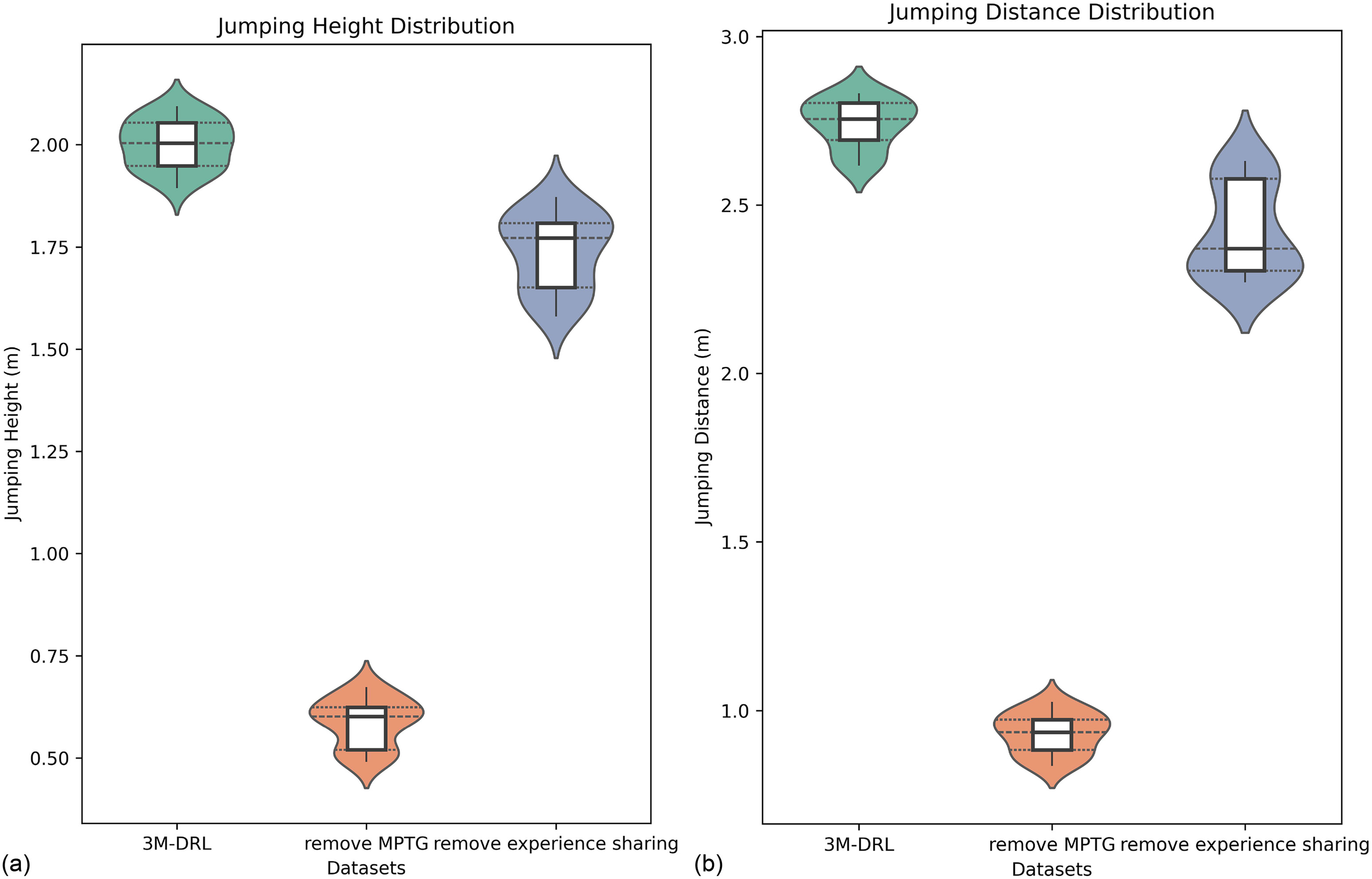
In addition, the violin plots (Fig. 17) provide a comprehensive statistical analysis of the data distribution from 20 jumps. The width of the violin corresponds to the probability density of the data at different values, while the embedded box plot reveals key statistical measures, including the median, quartiles, and potential outliers. The comparison of violin plots shows further that the difference in removing MPTG is still mainly reflected in the significantly reduced mean value of height and distance, while the centralization of height and distance data distribution does not have obvious disadvantages.
Moreover, in the platform terrain jumping task, the limitations become evident as the robot fails to overcome substantial obstacles. The insufficient height and distance diminish the inherent advantages of jumping under a low-gravity environment compared with other locomotion gaits.
Effect of Multistage Reward
To investigate the impact of the multistage reward on training effectiveness, it was replaced with a generic reward that does not differentiate between various stages of the task, emphasizing only the speed and energy consumption. Snapshots of the two tasks are given in Figs. 12(b) and 14(b). The robot body trajectory in Figs. 13 and 15 and the jumping metrics in Tables 2 and 3 further demonstrate the consequences of the absence of the multistage reward. In both jumping tasks, removing the fine-grained optimization provided by the multistage reward structure leads to a failure in balancing diverse requirements at each stage. Despite the continued integration of MPTG, the robot attempts to achieve a significant jump height but ultimately topples backward, unable to finish a complete jump.
| Metric | 3M-DRL | SAC | Remove MPTG | Remove multistage reward | Remove experience sharing |
|---|---|---|---|---|---|
| Landing on the platform: success () | T | F | F | F | T |
| Jumping off the platform: success () | T | F | F | F | F |
| Keep jumping: success () | T | F | F | F | F |
Effect of Experience Sharing
To evaluate the contributions of experience sharing to each of the two jumping tasks, separate training sessions were conducted for each task while maintaining consistent settings of other parameters. The snapshots demonstrating the results of these separate training are presented in Figs. 12(c) and 14(c).
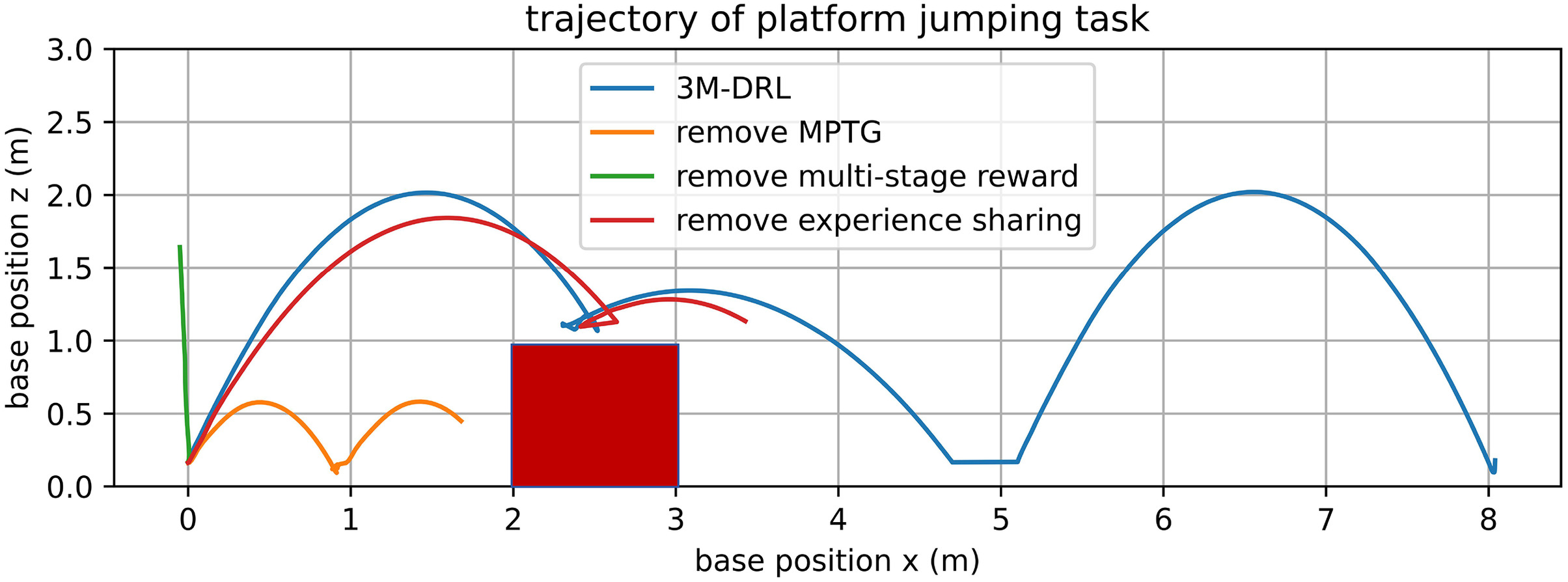
In the plane terrain jumping task, the completion of the task is not affected by the absence of experience sharing, as it mainly influences training data richness and efficiency. However, the performance of these jumps is less optimal than with a full algorithm. There are noticeable disparities in the robot’s jumping posture and landing strategy due to the lack of experience data from the platform jumping task. With experience sharing, the robot tends to adopt a posture with the body tilted upward, whereas, in separate training, it exhibits a flatter bounce. The jumping posture with the body tilted upward leads to more successful jumps, which is supported by the jump trajectory in Fig. 13, the metrics in Table 2, and the training convergence comparison illustrated in Fig. 16. The violin plots (Fig. 17) of removing experience sharing show a slightly lower average jump height and distance than 3M-DRL but has a wider distribution of jumping height and distance, which means that the stability of ultimate jumping ability has been reduced. The immature limb coordination trained after removing experience sharing not only reduces the maximum jumping performance but also potentially impacts the robot’s ability to consistently achieve a particular jump height and distance.
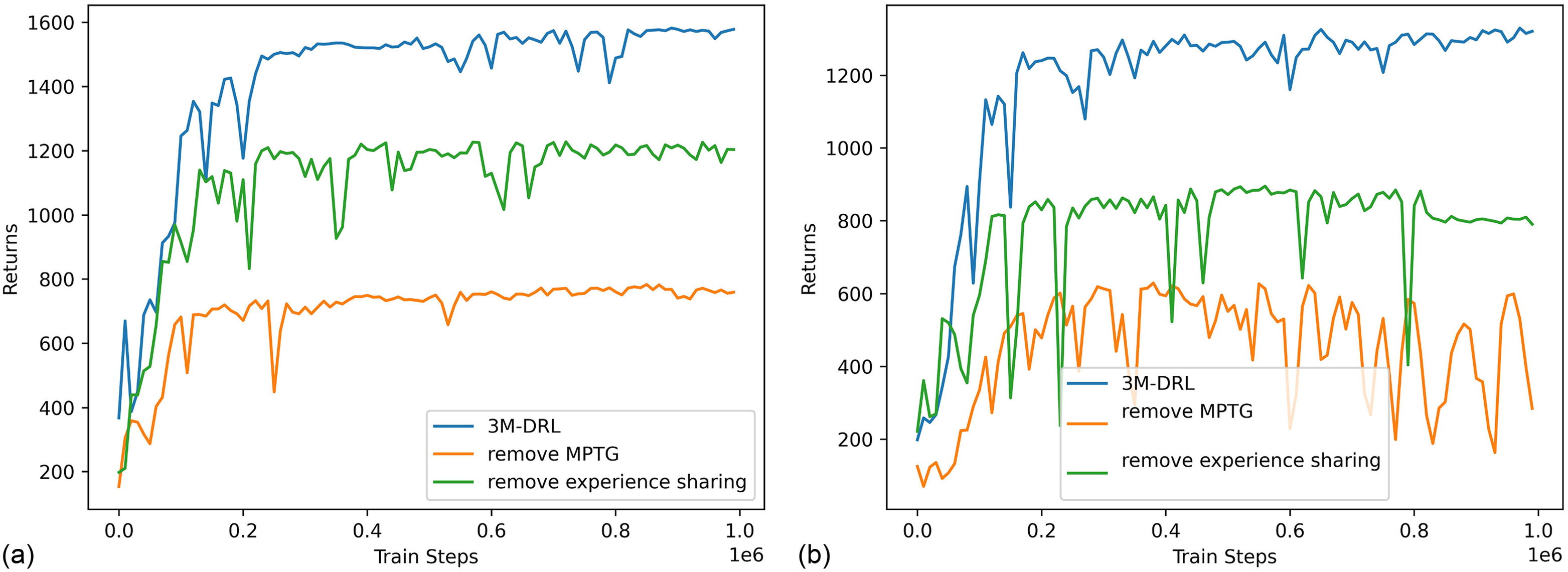
In the platform jumping task, the impact of experience sharing is more prominent. Lack of successful jumping experiences on plane terrain hinders the robot’s ability to perform delicate trade-offs between achieving a greater height and ensuring stable platform landings. The robot performs forward jumps, surpasses the platform’s height with distorted actions, and eventually falls onto the platform. Subsequent attempts to readjust its posture and jump off the platform lead to a loss of balance, causing the robot to be expelled due to excessive body tilt. Further, the convergence plots of the training process (Fig. 16) show the role of experience sharing in optimizing data utilization efficiency.
Conclusion
This paper presents the 3M-DRL algorithm, a novel approach designed for effective jumping in lunar gravity. By integrating the MPTG, multistage reward, and multitask experience-sharing, 3M-DRL aims to guide the learning process efficiently, tackle the challenges of defining complex jump rewards, and improve data utilization. Simulation results show that the 3M-DRL framework significantly outperforms the baseline, achieving remarkable jumping distances and heights that exceed five times the robot’s body length and height, respectively. Ablation studies further reveal the contributions of each component. The removal of the MPTG results in a noticeable decrease in average jump height and distance, underlining its essential role in facilitating powerful jumps. The absence of the multistage reward leads to an inability to maintain balance in midair, underscoring the importance of fine-grained optimization. The elimination of multitask experience-sharing has negative impacts, such as poor limb coordination, scattered distribution of jump data, and impaired training convergence, highlighting the crucial role of experience-sharing in enhancing overall effectiveness in training.
Data Availability Statement
Some or all data, models, or codes that support the findings of this study are available from the corresponding author upon reasonable request.
Acknowledgments
This work was supported by the Strategic Priority Research Program of the Chinese Academy of Sciences, Grant No. XDA30010500, and the Lab funding of the Key Laboratory of Space Utilization, Grant No. CXJJ-22S021.
References
Ajallooeian, M., S. Gay, A. Tuleu, A. Spröwitz, and A. J. Ijspeert. 2013a. “Modular control of limit cycle locomotion over unperceived rough terrain.” In Proc., IEEE/RSJ Int. Conf. on Intelligent Robots and Systems. New York: IEEE.
Ajallooeian, M., S. Pouya, A. Sproewitz, and A. J. Ijspeert. 2013b. “Central pattern generators augmented with virtual model control for quadruped rough terrain locomotion.” In Proc., IEEE Int. Conf. on Robotics and Automation. New York: IEEE.
Aractingi, M., P.-A. Léziart, T. Flayols, J. Perez, T. Silander, and P. Souères. 2023a. “Controlling the solo12 quadruped robot with deep reinforcement learning.” Sci. Rep. 13 (1): 11945. https://doi.org/10.1038/s41598-023-38259-7.
Aractingi, M., P.-A. Léziart, T. Flayols, J. Perez, T. Silander, and P. Souères. 2023b. “A hierarchical scheme for adapting learned quadruped locomotion.” In Proc., 2023 IEEE-RAS 22nd Int. Conf. on Humanoid Robots. New York: IEEE.
Baek, D., A. Purushottam, and J. Ramos. 2022. “Hybrid LMC: Hybrid learning and model-based control for wheeled humanoid robot via ensemble deep reinforcement learning.” In Proc., IEEE/RSJ Int. Conf. on Intelligent Robots and Systems. New York: IEEE.
Bellegarda, G., and A. Ijspeert. 2022. “CPG-RL: Learning central pattern generators for quadruped locomotion.” IEEE Rob. Autom. Lett. 7 (4): 12547–12554. https://doi.org/10.1109/LRA.2022.3218167.
Bussola, R., M. Focchi, A. Del Prete, D. Fontanelli, and L. Palopoli. 2023. “Efficient reinforcement learning for jumping monopods.” Preprint, submitted September 13, 2018. https://arxiv.org/abs/2309.07038.
Chen, H., B. Wang, Z. Hong, C. Shen, P. M. Wensing, and W. Zhang. 2020. “Underactuated motion planning and control for jumping with wheeled-bipedal robots.” IEEE Rob. Autom. Lett. 6 (2): 747–754. https://doi.org/10.1109/LRA.2020.3047787.
Chignoli, M., S. Morozov, and S. Kim. 2022. “Rapid and reliable quadruped motion planning with omnidirectional jumping.” In Proc., IEEE Int. Conf. on Robotics and Automation. New York: IEEE.
Coumans, E., and Y. Bai. 2016. “Pybullet, a python module for physics simulation for games, robotics and machine learning.” Accessed May 15, 2023. https://github.com/bulletphysics/bullet3.
Ding, Y., A. Pandala, C. Li, Y.-H. Shin, and H.-W. Park. 2021. “Representation-free model predictive control for dynamic motions in quadrupeds.” IEEE Trans. Rob. 37 (4): 1154–1171. https://doi.org/10.1109/TRO.2020.3046415.
Gehring, C., S. Coros, M. Hutter, M. Bloesch, M. A. Hoepflinger, and R. Siegwart. 2013. “Control of dynamic gaits for a quadrupedal robot.” In Proc., IEEE Int. Conf. on Robotics and Automation. New York: IEEE.
Haarnoja, T., et al. 2018a. “Soft actor-critic algorithms and applications.” Preprint, submitted December 13, 2018. https://arxiv.org/abs/1801.01290.
Haarnoja, T., S. Ha, A. Zhou, J. Tan, G. Tucker, and S. Levine. 2018b. “Learning to walk via deep reinforcement learning.” Preprint, submitted December 26, 2018. https://arxiv.org/abs/1812.11103.
Haarnoja, T., A. Zhou, P. Abbeel, and S. Levine. 2018c. “Soft actor-critic: Off-policy maximum entropy deep reinforcement learning with a stochastic actor.” In Proc., 35th Int. Conf. on Machine Learning. New York: Proceedings of Machine Learning Research.
Haldane, D. W., M. M. Plecnik, J. K. Yim, and R. S. Fearing. 2016. “Robotic vertical jumping agility via series-elastic power modulation.” Sci. Rob. 1 (1): eaag2048. https://doi.org/10.1126/scirobotics.aag2048.
Iscen, A., K. Caluwaerts, J. Tan, T. Zhang, E. Coumans, V. Sindhwani, and V. Vanhoucke. 2018. “Policies modulating trajectory generators.” In Proc., 2nd Annual Conf. on Robot Learning. New York: Proceedings of Machine Learning Research.
Ji, G., J. Mun, H. Kim, and J. Hwangbo. 2022. “Concurrent training of a control policy and a state estimator for dynamic and robust legged locomotion.” IEEE Rob. Autom. Lett. 7 (2): 4630–4637. https://doi.org/10.1109/LRA.2022.3151396.
Ji, M., L. Zhang, and S. Wang. 2019. “A path planning approach based on q-learning for robot arm.” In Proc., 2019 3rd Int. Conf. on Robotics and Automation Sciences (ICRAS). New York: IEEE.
Johannink, T., S. Bahl, A. Nair, J. Luo, A. Kumar, M. Loskyll, J. A. Ojea, E. Solowjow, and S. Levine. 2019. “Residual reinforcement learning for robot control.” In Proc., IEEE Int. Conf. on Robotics and Automation. New York: IEEE.
Katayama, S., and T. Ohtsuka. 2022. “Whole-body model predictive control with rigid contacts via online switching time optimization.” In Proc., IEEE/RSJ Int. Conf. on Intelligent Robots and Systems. New York: IEEE.
Kolvenbach, H., E. Hampp, P. Barton, R. Zenkl, and M. Hutter. 2019. “Towards jumping locomotion for quadruped robots on the moon.” In Proc., IEEE/RSJ Int. Conf. on Intelligent Robots and Systems. New York: IEEE.
Lee, J., J. Hwangbo, L. Wellhausen, V. Koltun, and M. Hutter. 2020. “Learning quadrupedal locomotion over challenging terrain.” Sci. Rob. 5 (47): eabc5986. https://doi.org/10.1126/scirobotics.abc5986.
Li, H., T. Zhang, W. Yu, and P. M. Wensing. 2023a. “Versatile real-time motion synthesis via kino-dynamic MPC with hybrid-systems DDP.” In Proc., IEEE Int. Conf. on Robotics and Automation. New York: IEEE.
Li, Z., X. B. Peng, P. Abbeel, S. Levine, G. Berseth, and K. Sreenath. 2023b. “Robust and versatile bipedal jumping control through reinforcement learning.” Preprint, submitted February 19, 2023. https://arxiv.org/abs/2302.09450.
Li, Z., X. Zeng, and S. Wang. 2021. “Hopping trajectory planning for asteroid surface exploration accounting for terrain roughness.” Trans. Jpn. Soc. Aeronaut. Space Sci. 64 (4): 205–214. https://doi.org/10.2322/tjsass.64.205.
Luo, B., and Y. Luo. 2022. “A balanced jumping control algorithm for quadruped robots.” Rob. Auton. Syst. 158 (Mar): 104278. https://doi.org/10.1016/j.robot.2022.104278.
Manchester, Z., and S. Kuindersma. 2017. “Variational contact-implicit trajectory optimization.” In Proc., Int. Symp. of Robotics Research. Cham, Switzerland: Springer.
Nahrendra, I. M. A., B. Yu, and H. Myung. 2023. “Dreamwaq: Learning robust quadrupedal locomotion with implicit terrain imagination via deep reinforcement learning.” In Proc., IEEE Int. Conf. on Robotics and Automation. New York: IEEE.
Nguyen, Q., M. J. Powell, B. Katz, J. D. Carlo, and S. Kim. 2019. “Optimized jumping on the MIT cheetah 3 robot.” In Proc., IEEE Int. Conf. on Robotics and Automation. New York: IEEE.
Pinosky, A., I. Abraham, A. Broad, B. Argall, and T. D. Murphey. 2023. “Hybrid control for combining model-based and model-free reinforcement learning.” Int. J. Rob. Res. 42 (6): 337–355. https://doi.org/10.1177/02783649221083331.
Qi, J., H. Gao, H. Su, L. Han, B. Su, M. Huo, H. Yu, and Z. Deng. 2023a. “Reinforcement learning-based stable jump control method for asteroid-exploration quadruped robots.” Aerosp. Sci. Technol. 142 (Jun): 108689. https://doi.org/10.1016/j.ast.2023.108689.
Qi, J., H. Gao, H. Yu, M. Huo, W. Feng, and Z. Deng. 2023b. “Integrated attitude and landing control for quadruped robots in asteroid landing mission scenarios using reinforcement learning.” Acta Astronaut. 204 (Jan): 599–610. https://doi.org/10.1016/j.actaastro.2022.11.028.
Rana, K., V. Dasagi, J. Haviland, B. Talbot, M. Milford, and N. Sünderhauf. 2023. “Bayesian controller fusion: Leveraging control priors in deep reinforcement learning for robotics.” Int. J. Rob. Res. 42 (3): 123–146. https://doi.org/10.1177/02783649231167210.
Roscia, F., M. Focchi, A. Del Prete, D. G. Caldwell, and C. Semini. 2023. “Reactive landing controller for quadruped robots.” IEEE Rob. Autom. Lett. 8 (Sep): 7210–7217. https://doi.org/10.1109/LRA.2023.3313919.
Sang, H., and S. Wang. 2022. “Motion planning of space robot obstacle avoidance based on DDPG algorithm.” In Proc., IEEE Int. Conf. on Service Robotics. New York: IEEE.
Shi, H., B. Zhou, H. Zeng, F. Wang, Y. Dong, J. Li, K. Wang, H. Tian, and M. Q.-H. Meng. 2022. “Reinforcement learning with evolutionary trajectory generator: A general approach for quadrupedal locomotion.” IEEE Rob. Autom. Lett. 7 (2): 3085–3092. https://doi.org/10.1109/LRA.2022.3145495.
Srouji, M., J. Zhang, and R. Salakhutdinov. 2018. “Structured control nets for deep reinforcement learning.” In Proc., 35th Int. Conf. on Machine Learning. New York: Proceedings of Machine Learning Research.
Tan, J., T. Zhang, E. Coumans, A. Iscen, Y. Bai, D. Hafner, S. Bohez, and V. Vanhoucke. 2018. “Sim-to-real: Learning agile locomotion for quadruped robots.” Preprint, submitted April 27, 2018. https://arxiv.org/abs/1804.10332.
Villarreal, O., V. Barasuol, P. M. Wensing, D. G. Caldwell, and C. Semini. 2020. “MPC-based controller with terrain insight for dynamic legged locomotion.” In Proc., IEEE Int. Conf. on Robotics and Automation. New York: IEEE.
Yu, M., S. Li, X. Huang, and S. Wang. 2018. “A novel inertial-aided feature detection model for autonomous navigation in planetary landing.” Acta Astronaut. 152 (Dec): 667. https://doi.org/10.1016/j.actaastro.2018.09.022.
Zhang, C., W. Zou, L. Ma, and Z. Wang. 2020. “Biologically inspired jumping robots: A comprehensive review.” Rob. Auton. Syst. 124 (Feb): 103362. https://doi.org/10.1016/j.robot.2019.103362.
Zhu, L., J. Ma, and S. Wang. 2019. “Deep neural networks based real-time optimal control for lunar landing.” In Proc., 3rd Int. Conf. on Aeronautical Materials and Aerospace Engineering. Bristol, UK: IOP Publishing.
Information & Authors
Information
Published In

Journal of Aerospace Engineering
Volume 37 • Issue 6 • November 2024
Copyright
This work is made available under the terms of the Creative Commons Attribution 4.0 International license, https://creativecommons.org/licenses/by/4.0/.
History
Received: Dec 5, 2023
Accepted: May 14, 2024
Published online: Aug 2, 2024
Published in print: Nov 1, 2024
Discussion open until: Jan 2, 2025
ASCE Technical Topics:
- Aerospace engineering
- Algorithms
- Architectural engineering
- Architecture
- Artificial intelligence (AI)
- Artificial intelligence and machine learning
- Astronomy
- Automation and robotics
- Business management
- Computer programming
- Computing in civil engineering
- Continuum mechanics
- Dynamics (solid mechanics)
- Engineering fundamentals
- Engineering mechanics
- Innovation
- Mathematics
- Moon
- Motion (dynamics)
- Neural networks
- Practice and Profession
- Solid mechanics
- Systems engineering
Authors
Metrics & Citations
Metrics
Citations
Download citation
If you have the appropriate software installed, you can download article citation data to the citation manager of your choice. Simply select your manager software from the list below and click Download.