Automatic Classification of Construction Work Codes in Bill of Quantities of National Roadway Based on Text Analysis
Publication: Journal of Construction Engineering and Management
Volume 149, Issue 2
Abstract
The construction work classification code is a crucial index for consistently collecting unit cost data from the bill of quantities (BOQ). Appropriate classification codes assigned to detailed construction work item descriptions are required to verify project cost and for quality control. However, the codification system is complicated and time consuming for estimators to follow. This study proposes a framework to recognize the text of detailed construction work item descriptions in the BOQ and automatically assign the most similar work classification code. The automatic assignment algorithm was designed to score the similarity of the tokenized words in the work item description based on whether they contain the same word. The framework was experimented with using the national roadway BOQ; this BOQ is used for the procurement process in South Korea. It transformed work item descriptions from unstandardized BOQs into standardized data with more than 91.12% accuracy. The results of this study can be used as a prerequisite step for standardizing construction life cycle cost data and the automatic generation of BOQs.
Introduction
A significant quantity of documents is generated during the construction project, such as the bill of quantities (BOQ), drawings, and specifications (Al Qady and Kandil 2015; Ndekugri and McCaffer 1988). The BOQ generated in the early stage of construction is particularly, important because the preliminary estimates written in the document are the first step in collecting the construction cost data (Martínez-Rojas et al. 2016). However, the importance of standardization of the BOQ is often ignored, specifically in South Korea, and BOQs are prepared in an in-house unstandardized format that most engineering firms are accustomed to using. This hinders the verification of unit costs of the detailed works in construction projects and makes it challenging to collect valid cost data during the construction phases.
Accordingly, the Korean Public Procurement Service provides a standard work classification code (WCC) with the standard work item description (WID) for quantity surveyors and estimators to guide them in preparing BOQs as a standardized format (PPCS 2021). This Korean standard WCC originates from the United Kingdom’s Civil Engineering Standard Method of Measurement (Barnes 1992; Barnes and Attridge 2019) and follows the cost breakdown structure. The standard WCC is represented with 12 digits, for example, “CDD100200000,” and the letters and numbers represent the categories of the construction works. Assigning an appropriate WCC to each detailed WID in the BOQ helps to verify the construction cost when reviewing multiple BOQs and estimate the future construction cost. However, matching the most suitable WCC to each detailed WID is difficult because estimators cannot be expected to memorize and recognize all the hierarchical structures of the entire codification system. Consequently, the estimators do not follow the standard WCC, or different results are obtained depending on the estimator’s disposition. Several studies have introduced automatic classification approaches to address this problem related to BOQs (Jeong 2020; Martínez-Rojas et al. 2015). Nevertheless, the rate of standardized BOQs with properly matched WCCs with WIDs is meager. Such unstandardized BOQs, by which is meant a BOQ not matched with the suitable WCC, has lowered the transparency and reliability of construction costs (Jalam et al. 2018; Juszczyk et al. 2014; Razali et al. 2014). This is because it is difficult for the public procurement servicer to check the unit cost for the same details when the WCC is not assigned. These conditions reduce the reliability of the estimate due to the high probability of errors, for example, duplicated quantity calculations and omissions. Also, it leads to the rewriting of new documents related to costs when managing construction costs during the construction phase (Powell 2012).
Thus, this research aims to develop a framework of automatically assigning a standard WCC to a detailed WID to make a standardized BOQ. Until now, the automatic assignment of work classification codes was performed only in the first level of construction classification (Martínez-Rojas et al. 2018) or in a specific activity type, such as tiling (Jeong 2020). However, this research targets the allocation of a standard WCC to the lowest level of construction work items in the BOQ. The algorithm automatically allocates the most suitable WCC based on word inclusions in the detailed WID of the BOQ. This research will contribute to using construction life cycle cost data and the automatic generation of BOQs by supporting standardized data collection.
The rest of this paper is organized as follows. The next section reviews the importance of the BOQ and the previous studies related to the standard measurement methods. Also, the construction text classification techniques are summarized in this section. In section “Research Methodology,” the research methodologies and experimental processes for automatic code assignment are explained. The section “Results and Discussion” sets out the results and discussion. Finally, the “Conclusions” section completes the paper by explaining the contributions of the research and future opportunities arising from it.
Literature Review
Bill of Quantities and Standard Measurement Methods in Korea
The BOQ is a document that includes lists of brief descriptions of work items with estimated quantities and unit costs of the construction task (Seeley 1993). As shown in Table 1, each line of the WID in the BOQ requires quantities and unit cost; the cost is composed of materials, labor, expenses, and total cost. Those data are filled out by quantity surveyors and estimators in the early stage of the construction project for procurement and contract. Even after the procurement process, they can be used as base data for design changes, interim payment, and final payment (Kang and Paulson 1997). Therefore, an accurate and well-organized BOQ prepared by an experienced expert is important (Cunningham 2014) to provide adequate and precise evidence for the construction project.
| Pricing category | Work classification code | Work item description | Detailed specification | Unit | Quantity | Material | Labor | Expenses | Total | ||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Unit cost | Total amount | Unit cost | Total amount | Unit cost | Total amount | Unit cost | Total amount | ||||||
| Text | — | .1. Earth work | — | — | — | — | — | — | — | — | — | — | — |
| Text | — | .1.04 Earth cutting | — | — | — | — | — | — | — | — | — | — | — |
| Standard market price | CDD100200000 | .a. Soil cutting | Dozer 32 ton | 93,343.0 | 410.0 | 38,270,630 | 296.0 | 27,629,528 | 281.0 | 26,229,383 | 987.0 | 92,129,541 | |
| Standard market price | CDD200000000 | .b. Ripping rock cutting | Dozer 32 ton | 8,051.0 | 702.0 | 5,651,802 | 535.0 | 4,307,285 | 489.0 | 3,936,939 | 1,726.0 | 13,896,026 | |
| Text | — | .c. Blasting rock cutting | — | — | 0.0 | 0.0 | 0 | 0.0 | 0 | 0.0 | 0 | 0.0 | 0 |
| Equip. cost pricing | PB108130203 | …c-1. Breaker | Excavator | 38,488.0 | 5,570.0 | 214,378,160 | 13,113.0 | 504,693,144 | 9,760.0 | 375,642,880 | 28,443.0 | 1,094,714,184 | |
| Text | — | .1.05 Hauling excavated soil | — | — | 0.0 | 0.0 | 0 | 0.0 | 0 | 0.0 | 0 | 0.0 | 0 |
| Text | — | .a. Hauling without costing | — | — | 0.0 | 0.0 | 0 | 0.0 | 0 | 0.0 | 0 | 0.0 | 0 |
| Operating cost | E0010101000Z0001 | …a-1. Soil | — | 37,841.0 | 0.0 | 0 | 0.0 | 0 | 0.0 | 0 | 0.0 | 0 | |
| Operating cost | E0010101000Z0002 | …a-2. Ripping rock | — | 1,212.0 | 0.0 | 0 | 0.0 | 0 | 0.0 | 0 | 0.0 | 0 | |
| Operating cost | E0010101000Z0003 | …a-3. Blasting rock | — | 3,615.0 | 0.0 | 0 | 0.0 | 0 | 0.0 | 0 | 0.0 | 0 | |
| Text | — | .b. Dozer hauling | — | — | 0.0 | 0.0 | 0 | 0.0 | 0 | 0.0 | 0 | 0.0 | 0 |
| Equip. cost pricing | TCDI21211N0 | …b-1. Soil | (dozer 32 ton) | 4,151.0 | 501.0 | 2,079,651 | 211.0 | 875,861 | 344.0 | 1,427,944 | 1,056.0 | 4,383,456 | |
| Equip. cost pricing | TCDI21212N0 | …b-2. Ripping rock | (dozer 32 ton) | 221.0 | 861.0 | 190,281 | 363.0 | 80,223 | 592.0 | 130,832 | 1,816.0 | 401,336 | |
| Equip. cost pricing | TCDI21213N0 | …b-3. Blasting rock | (dozer 32 ton) | 338.0 | 1,598.0 | 540,124 | 674.0 | 227,812 | 1,100.0 | 371,800 | 3,372.0 | 1,139,736 | |
| Text | — | .c. Dump hauling | — | — | 0.0 | 0.0 | 0 | 0.0 | 0 | 0.0 | 0 | 0.0 | 0 |
| Equip. cost pricing | TCDI21311N1 | …c-1. Soil | (dump 15 ton + loader) | 135,085.0 | 1,706.0 | 230,455,010 | 1,398.0 | 188,848,830 | 1,316.0 | 177,771,860 | 4,420.0 | 597,075,700 | |
| Equip. cost pricing | TCDI21312N1 | …c-2. Ripping rock | (dump 15 ton + loader) | 11,337.0 | 3,161.0 | 35,836,257 | 2,629.0 | 29,804,973 | 2,515.0 | 28,512,555 | 8,305.0 | 94,153,785 | |
| Equip. cost pricing | TCDI21313N0 | …c-3. Blasting rock | (dump 15 ton + backhoe) | 34,534.0 | 4,993.0 | 172,428,262 | 5,149.0 | 177,815,566 | 4,347.0 | 150,119,298 | 14,489.0 | 500,363,126 | |
| Text | — | .1.06 Hauling imported soil | — | — | 0.0 | 0.0 | 0 | 0.0 | 0 | 0.0 | 0 | 0.0 | 0 |
| Equip. cost pricing | O108A10020 | .a. Soil | Imported from Zone 1 | 23,337.0 | 3,020.0 | 70,477,740 | 1,681.0 | 39,229,497 | 2,388.0 | 55,728,756 | 7,089.0 | 165,435,993 | |
Note: Unit = Korean Won (KRW); and 1 USD = approximately 1,269 KRW in May 2022.
In this context, the classification of the WID plays a significant role in structuring the information and maintaining the consistency of data from the design and construction stages to the maintenance stage of the project (Ekholm 1996). Cost breakdown structure is a hierarchical category that classifies all kinds of costs (Le et al. 2009). The WCC based on the cost breakdown structure is recommended to be allocated to a WID in the BOQ. The standard WCC representing the cost breakdown structure is a key index for managing cost data throughout the life cycle of a construction project. In the United Kingdom, the standard WCC was regulated in the Civil Engineering Standard Method of Measurement in 1976 and has been put down next to the detailed item in construction work. In South Korea, the Public Procurement Service published a standardized WCC to the public for standardizing BOQ in 1999 by benchmarking the UK’s systems (Yun 2010).
The hierarchy of the main class and subclasses of the Korean cost breakdown structure and examples of 12-digit WCCs are shown in Fig. 1. The first digit in the standard WCC stands for the major categories of construction work, such as architecture, civil engineering, electrical, mechanical, and cultural heritage repair. The following digits are the subdivisions of cost breakdown structure, and detailed construction works are gradually classified. Finally, one unit cost can be matched to one WID next to the standard WCC. When costs are calculated in the subdivision of construction work using the standard WCC sophistically, budget omission can be minimized, and the accuracy of cost estimation can be improved (Cerezo-Narváez et al. 2020). However, many of BOQs are often composed of their own company codes whose implied meaning is unknown, such as “TCDI21311N1” and “O108A10020,” as shown in Table 1. In this case, it is challenging to collect unit costs because there is no standard index as a basis for data collection.
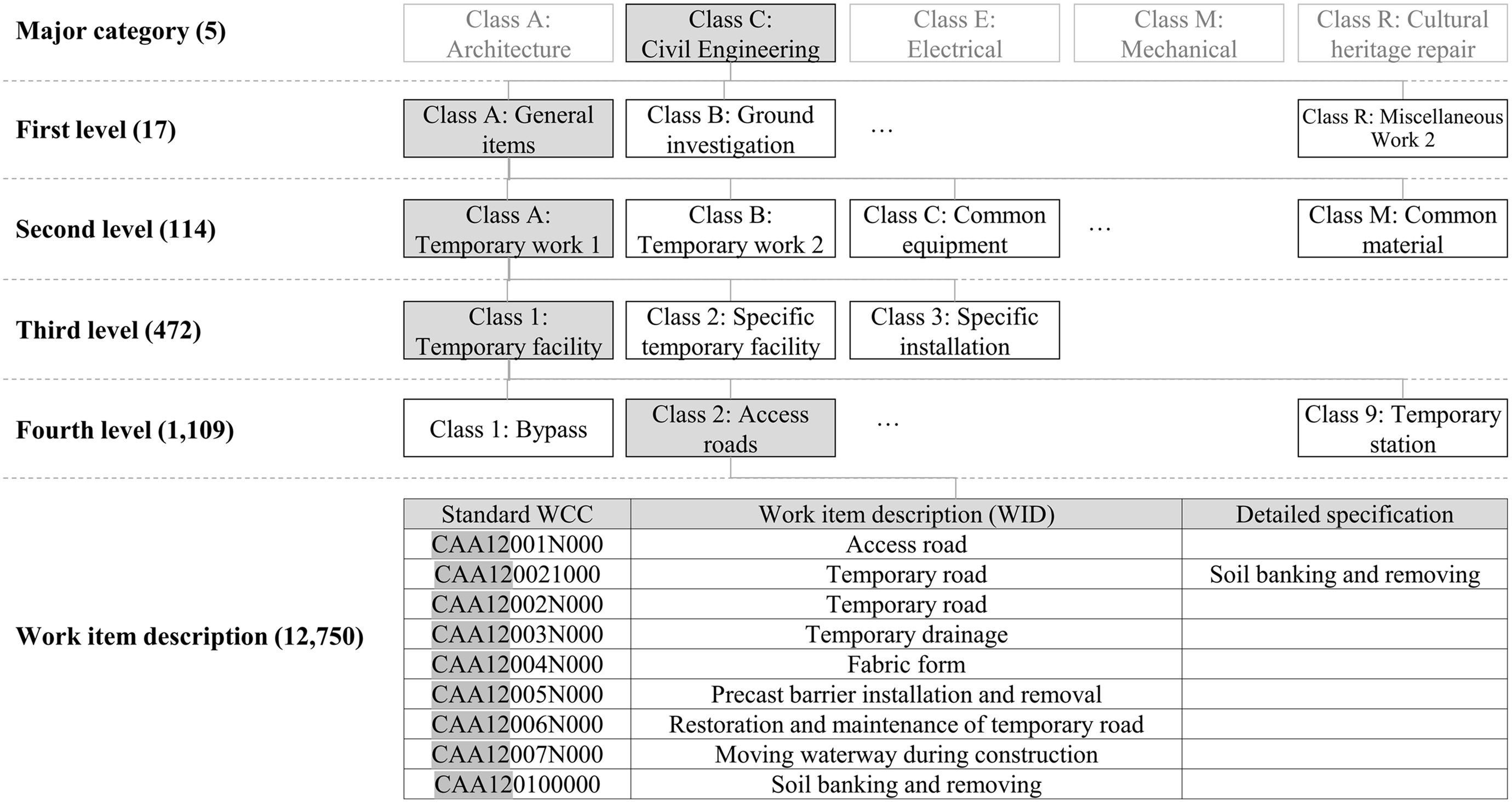
Over recent years, many researchers and organizations have attempted to improve standard measurement methods for the successful management of construction projects’ costs and schedules (Cho et al. 2013; Jung and Gibson 1999). The Public Procurement Service in South Korea, which conducts public construction project contracts and price surveying, provides a system named C3R (i.e., construction cost-accounting compatible regulations) for unified BOQs. However, quantity surveyors and cost estimators do not use the standard WCC but rather submit BOQs to a contractor in a nonunified format by using their own company’s code. The situation is similar in other countries. Martínez-Rojas et al. (2016) in Spain said that the structure and linguistics of BOQs vary among practitioners without standards, making the acquisition and management of the information contained in the BOQ laborious. In Malaysia, standard measurement methods have been required to generate easy and clear BOQs (Akbar et al. 2015; Bandi et al. 2014; Rashid et al. 2006), and Akbar et al. (2015) claimed that the process should be automated and carried out in a more scientific manner. In Australia and New Zealand, the Australian and New Zealand Standard Method of Measurement (ANZSMM) was published in 2018 to provide consistent guidance for the measurement of building works. However, Senaratne and Rodrigo (2019) said that adhering to a standard method of measurement to prepare an accurate BOQ is tedious for any quantity surveyor and needs to be simplified to improve efficiency. In this context, the authors identified the necessity of an automatic assignment method that has been defined for the preparation of standardized BOQ.
Text Classification Techniques for Construction-Related String Data
In the construction management field, text classification plays a major role in document structuring, specification review, and cost calculation (Ekholm 1996). Several text classification techniques have been developed to categorize and structure the set of text information into predefined classes (Kesavaraj and Sukumaran 2013). Caldas and Soibelman (2003) proposed construction project document classification methods according to the Construction Industry Competency Standard (CICS) items. They explained the concept of the vectorization of the text for interpretation of the text features. Caldas and Soibelman (2003) also compared four well-known classification methods—naïve Bayes, -nearest neighbor, Rocchio, and support vector machine algorithms—to classify documents. They applied a hierarchical classification of product documents from a construction product database according to their corresponding Construction Specifications Institute (CSI) MasterFormat division. Similarly, Al Qady and Kandil (2015) classified documents by discourse and retrieved the most relevant documents automatically from past projects. In recent years, state-of-the-art machine learning techniques have been widely used for text classification in construction. Mo et al. (2020) proposed a machine learning–based classification model that assigned and prioritized work orders for building maintenance, achieving 77% accuracy. Moon et al. (2021) developed semantic text-pairing techniques for relevant provision identification during the construction specification review process using a Doc2Vec model.
Nevertheless, experiments for automatically assigning a work classification code for a short string of descriptions in BOQs have had relatively little attention (Martínez-Rojas et al. 2016; Sequeira and Lopes 2015). Much of the research related to BOQs has focused on collaborative editing techniques and electronic document-sharing (Wang et al. 2015). However, as text-mining techniques have been actively developed, several studies have been conducted to classify construction work item description using text in BOQs. Martínez-Rojas et al. (2015) developed a mechanism for automatically extracting information from the work descriptions and storing it in a predefined hierarchical BOQ structure. The research was based on a multicriteria aggregation process, based in turn on expert knowledge and learned information. In their continuing research, they have classified the work descriptions in BOQs of residential buildings by using text classification algorithms (Martínez-Rojas et al. 2018). However, in their research, data with a lack of features were excluded from the experimental scope and classified work descriptions at the first level of the work breakdown structure. In Korea, Jeong (2020) proposed a framework for classifying work descriptions in BOQs using Jaro–Winkler distance; however, the algorithm was limited to tiling tasks only. To overcome the limitations of current BOQ text analysis studies, this research aims to assign WCCs to the lowest level of the construction work item and for this to be applied in all construction works.
Research Methodology
Research Framework
This research proposes a framework to standardize BOQs by assigning a standard WCC to a detailed WID. The BOQ data used in the research were from the document prepared for the national roadway construction project in South Korea. Most of the BOQs for national roadway construction included road, bridge, and tunnel works. The research was composed of three phases, as shown in Fig. 2: (1) preprocessing, (2) similarity scoring and string matching, and (3) Evaluation.
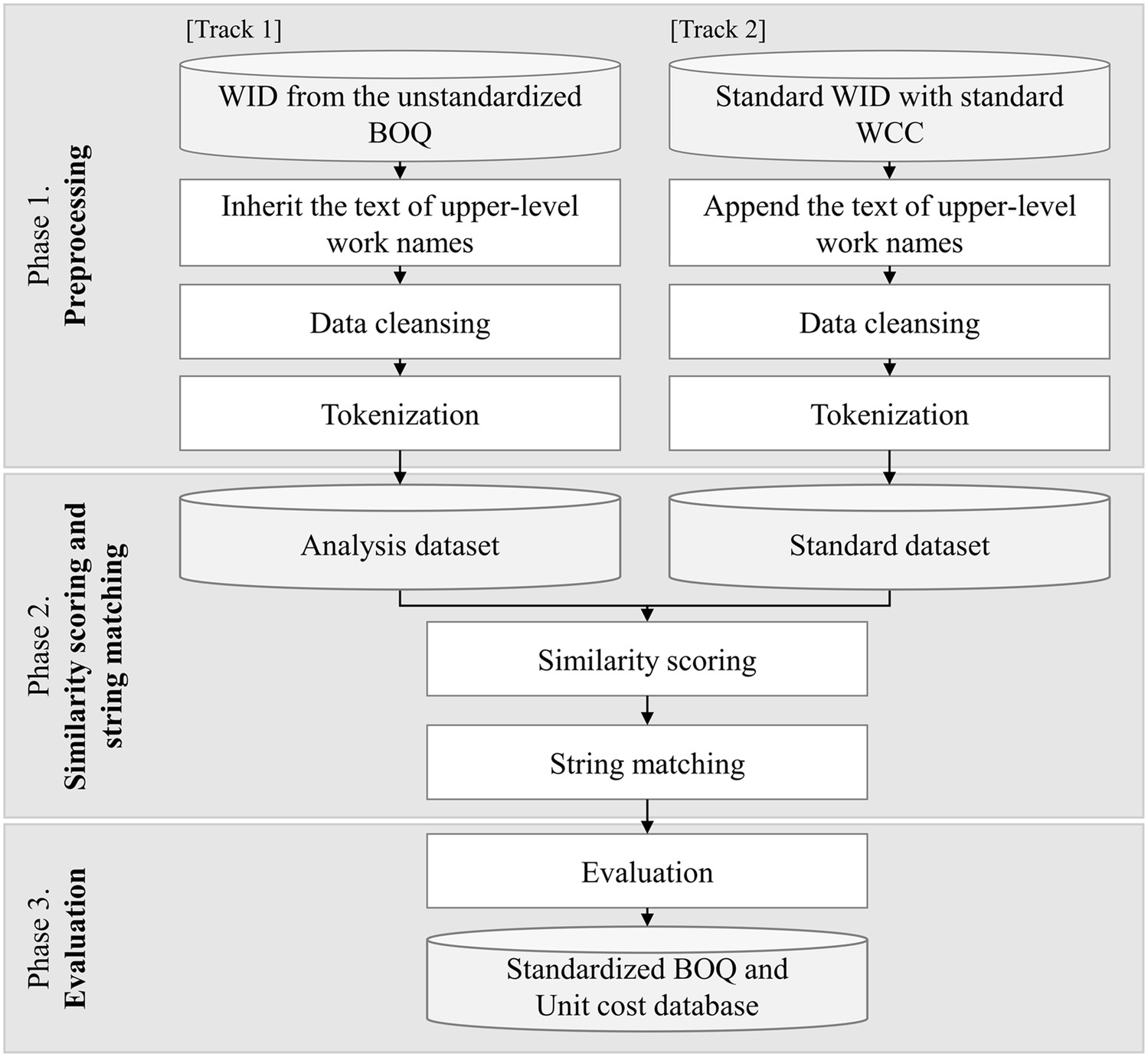
The first phase, preprocessing of the BOQ data, proceeded on two tracks. One track was to make analysis data sets using the WIDs in unstandardized BOQs. The analysis data set comprised 44 unstandardized BOQ documents used for the procurement process for national roadway construction projects from 2016 to 2020. The project scope was confined to the value of the construction, which was more than 20 billion Korean won (approximately USD 16 million). The other track generated the standard data set using standard WIDs with standard WCCs provided by the Public Procurement Service in 2020. The document of standard WCCs contained 12,750 rows of standard WIDs. Each row represented a detailed explanation of one standard WCC.
The second phase was to score the similarity between the string from the analysis data set and the standard data set to assign the most suitable standard WCC. The similarity scoring algorithm presented in this framework scored the similarity by comparing the one detailed WID from the analysis data set to all standard WIDs from the standard data set. The most similar standard WCC with the highest similarity score was chosen and returned the final assignment result matching the WID in the analysis data set.
The final phase was the evaluation process, for checking the reliability of the framework for similarity scoring and string matching. The authors reviewed the assigned results and set the threshold of the similarity score to divide whether correctly matched or not. After the evaluation process was done, the unit cost data of the WIDs from BOQ were collected and saved for future database establishment.
A detailed explanation of each process follows in the next section. The data preprocessing, such as amplifying the string information and cleansing the unnecessary expressions, was done for better string matching performance. Next, the authors devised an automatic assignment algorithm to match the standard WCC to the WID in unstandardized BOQ. Finally, the authors stored the unit cost of each WID with a standardized BOQ in the database and discussed the different performances of the string match algorithm by the work classification.
Data Preprocessing
Both analysis data sets and standard data sets were text data requiring preprocessing. A computerized approach to analyzing text is natural language processing (NLP) (Liddy 2001). In general, the first step of NLP is to feature extraction from text data. However, the original text strings of detailed WIDs from unstandardized BOQs consisted of a tiny number of words, just two or three, which was insufficient for extracting features. That is to say, one WID had a lack of information for computers to classify and assign the most proper WCC. For example, “Concrete lining” work under the “Tunnel” work division and “Concrete” under the “Road” work division were completely different types of work, but the word “Concrete” on its own could not show which division the work item was inherited from. Thus, a series of tasks were required to amplify recognizable information to improve the performance of text information extraction. The authors supplemented the text information by inheriting the words of the work name from higher levels of the WID.
The two data sets of WIDs had different forms of composition; thus, the data preprocessing was done separately. The analysis data set composed of WIDs from unstandardized BOQs was preprocessed, as shown in Fig. 3. Most of the BOQs were written in .xlsx or .xml format, and the information was written in a separate cell in the inconsistent form. Therefore, the authors had to devise an aligning method to restructure the data. As illustrated in Fig. 3, upper-level work names such as Level 1 (rows highlighted by a black straight line), Level 2 (rows highlighted by a dotted line), and Level 3 (rows highlighted by a dashed line) were attached in front of the final WID level (i.e., Level 4, highlighted in grey-blue) consecutively as a list. The process was automatically done with Python scripting using the RegEx module. If a representation meant the upper level of a work name, it was pasted to a lower level of the work name and returned in a single long string in the form of a list, as shown in Fig. 3. The words of text indicating the detailed specification of the work item such as “under 5–8 m” and “ excavator” were also attached to the end of the string list.
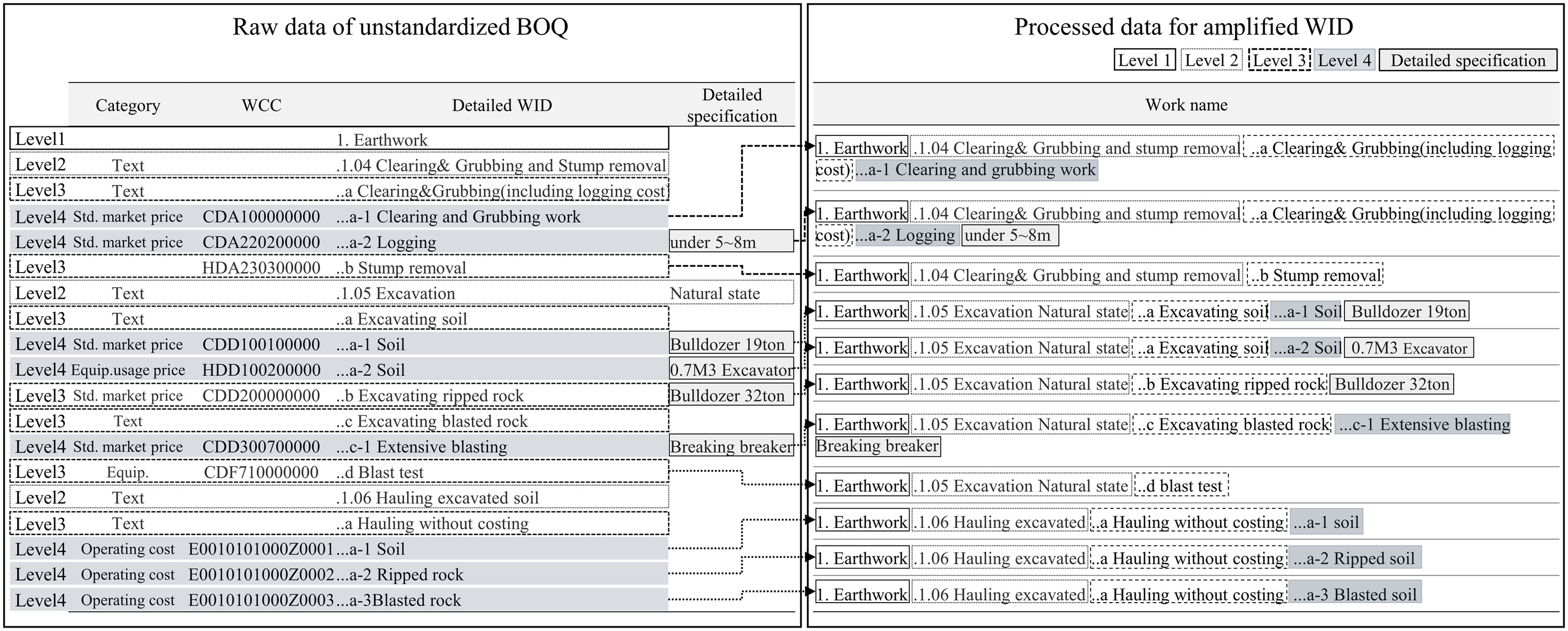
During the process of inheriting the text of the upper-level work name to the lower-level WID, unnecessary symbols (e.g., “1.”, “.1.04”, “.a”, “.a-1”) were also added. The authors coded to remove unnecessary data such as special characters or meaningless symbols, leaving only pure text. After the cleansing of unnecessary words, the tokenization process was followed (Webster and Kit 1992). Tokenization (Uysal and Gunal 2014) is the converting procedure of splitting a text into words, phrases, or other meaningful parts. More specifically, a token indicates a word, and tokenization is the act of splitting a phrase or collection of text into semantic word units (Islam and Inkpen 2008). In many cases, a space mark between the words was generally used as a delimiter to split the word units. In this research, the authors delimited the line of texts in amplified WIDs using the Open Korean Text library (OKT) in the KoNLPy package. KoNLPy is an open-source package for preprocessing Korean words, which splits the word into a stem and affix (Park and Cho 2014). After the tokenization process was completed, text information was stored in the form of a cleansed list. The analysis data set preparation for the similarity check process was thus completed.
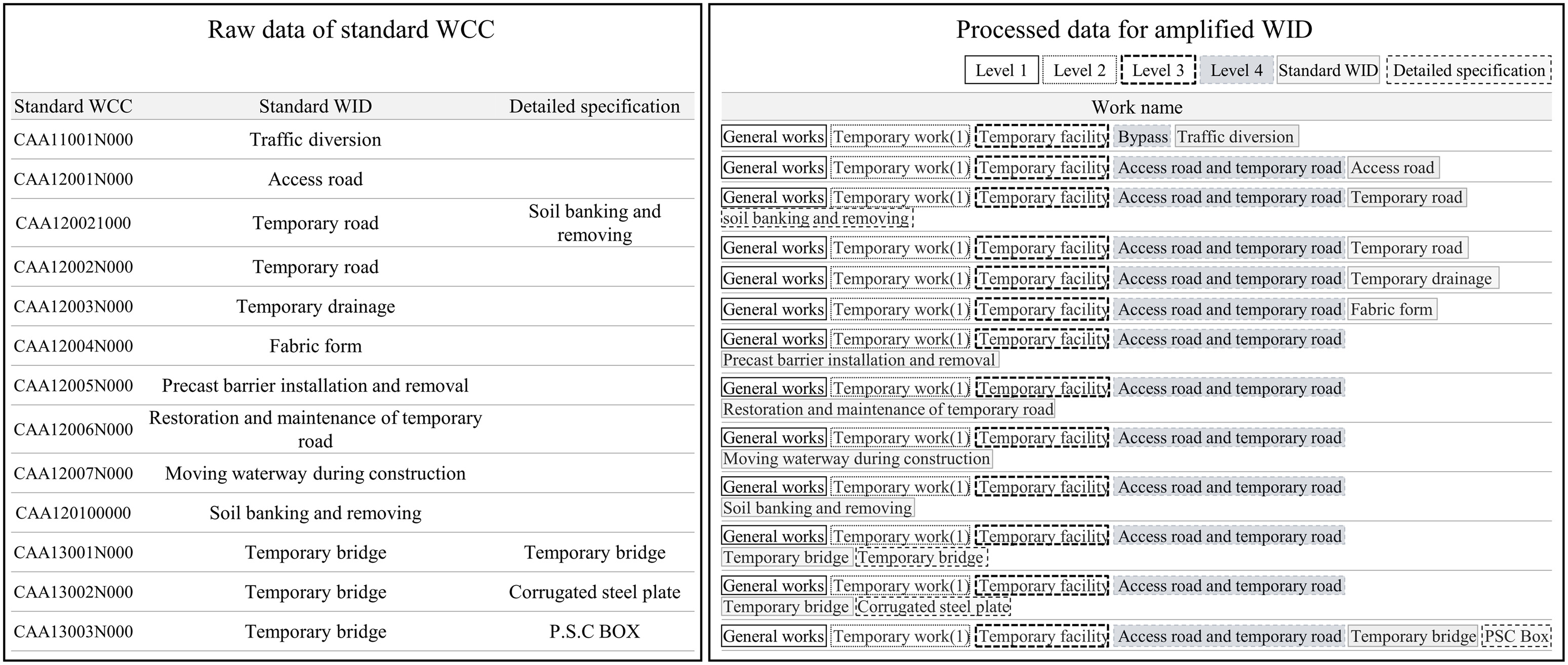
Similar data preprocessing was performed for the standard WID data set. The standard WID data set with the standard WCC also did not have information on the upper-level work names. Hence, the text of the upper-level work name had to be added to the standard WID. The major difference in the process from the analysis data set was that the authors merged the text of upper work names according to the information of the code digits. For instance, in Fig. 4, the second digit of the standard WCC “A,” the third digit “A,” and the fourth digit “1” indicate “General work,” “Temporary work,” and “Temporary facility,” respectively. The authors replaced the digit of the code with the word intended for amplifying WID data. Also, the text of the detailed specification column in the standard WCC was attached at the end of the WID string. Tokenization was performed in the same way and stored in the form of a list.
Similarity Scoring and String Matching
Text similarity is determined by how close two pieces of text are both lexically and semantically (Gomma and Fahmy 2013). Gomma and Fahmy (2013) suggested three similarity measuring approaches: string, corpus, and knowledge based. The corpus-based and knowledge-based approaches determine similarity between words according to information gained from large corpora or derived from semantic networks. This is contrary to string-based approaches, which measure the similarity of string sequences or character composition. String-based approaches calculate the similarity of lexical features, which means that they do not capture semantic similarities beyond trivial levels (Hua et al. 2015; Kenter and de Rijke 2015). The text length of WID data used in this study was short and insufficient to extract semantic similarity, and thus the authors decided that string-based lexical similarity was more suitable for WID text analysis.
An edit distance has been widely used for measuring short string similarity lexically, which requires the minimum number of insertions, deletions, and substitutions to transform one string into another for similarity matching (Ristad and Yianilos 1998). The Jaro–Winkler distance, a well-known edit distance measurement, was used in this study for matching two strings and calculating their similarity (Cohen et al. 2003). First, the Jaro distance of string similarity is calculated by Eq. (1)where = length of string from the analysis data set; = length of string from the standard data set; = same number of characters; and = amount of transposition.
(1)
Jaro–Winkler similarity adds weights for prefix-matching onto the Jaro distance, as in the following [Eq. (2)]where = length of the common prefix; and = constant scaling factor. The scale of the Jaro–Winkler similarity score ranges from 0 to 1. The authors made a preliminary test of the feasibility of using this similarity measurement for the BOQ text analysis by applying it into one selected BOQ. The project had 1,370 WIDs, and, as a result, the measurement found only 50.2% of string matches with a distance of 0.7 or greater. This result implied that only 50% of WIDs were standardized and correctly matched, which is insufficient for automated lexical string-matching. The authors thus determined that the simple comparison of tokenized words included in the text would be more effective for WIDs than the edit distance calculation; the authors devised a rule-based approach to match the standard WCC to unstandardized WID by checking the inclusion of the words.
(2)
The pseudocode in Fig. 5 describes the similarity-scoring algorithm to measure the lexical similarity between two strings from each data set (i.e., one WID from the analysis data set and the other WID from the standard data set). The algorithm scored similarity based on the inclusion of words. For example, if the word “logging” exists in the WID of the analysis data set and the WID of the standard data set, the overlapping word length is added to the similarity score. In the opposite direction, if the word of the WID from the standard data set is included in the WID from the analysis data set, then the similarity score is added as equivalent to the length of the same words. This scoring system is designed to minimize the similarity score not being added when adding a score only in one direction, such as “drainage” and “drain” (i.e., added similarity ). Each WID of the unstandardized BOQ (analysis data set) calculates the similarity score by examining the entire WID in the standard data set. Finally, the algorithm returns the optimal matching result with the highest similarity score.

After returning the WID of unstandardized BOQs with the most similar WIDs from the standard data set and the similarity score between the WIDs, the unit cost attached to the WID in the unstandardized BOQ and standard WCC stuck next to the standard WID were merged to complete the data assignment.
Evaluation of the Results
The assignment results were saved in .csv format. As mentioned before, the results contained the detailed WID from the analysis data set: the most similar standard WID and standard WCC, the similarity score between the two WIDs, and the unit cost of the WID. The previous work classification code assigned to the WID in the unstandardized BOQ was the same as the unlabeled data because most of the originally assigned WCCs did not follow the standard work classification code system. Cross-validation is difficult because there is no set of correct answers, and it is not a data set trained through machine learning. The arbitrary process of making correct answers and comparing them to automatically matched results was not carried out because there is room for different interpretations. The authors thus manually checked the standard WID, which was automatically assigned to detailed WIDs from unstandardized BOQs, and determined a threshold for distinguishing between two groups: accurately and not accurately assigned. The cut-off value of the morphological similarity score was set to two points based on the objective opinions of researchers at the Procurement Research Institute and related industry workers. The cut-off value was used as a threshold to evaluate the accuracy of the algorithm numerically. However, even if the similarity score were higher than the threshold value, there could be an incorrect match, or even if the similarity score were less than the threshold value, there could be correctly matched results. Therefore, the authors additionally compared the automatically matched results and discuss them in the “Results and Discussion” section. After evaluating the results manually, the authors established a unit cost database that shared the same WID to review the possibility of accurate cost estimation using the standardized WID.
Results and Discussion
The purpose of the experiments was to develop an algorithm for automatically assigning standard WCCs to the WIDs from unstandardized BOQs. The assignment results are summarized in Table 2. The collected 44 BOQs had a total of 68,890 lines of WID and an average of 1,565 WIDs in one BOQ. Among the 68,890 WIDs, 4.86% were lost during the preprocessing process due to unexpected expressions or written locations in unrecognizable fields. Thus, a total of 65,541 WIDs was used for the experiments, which means that about 1,490 WIDs with unit cost data could be collected from one BOQ.
| Number of BOQ | Original number of WID from BOQs | Number of WIDs with standard WCC assigned | Loss |
|---|---|---|---|
| 44 | 68,890 | 65,541 | 4.86% |
Review of the Similarity Scoring
The automatic assignment algorithm returned the similarity score between the detailed WID of the analysis data set and the standard WID of the standard data set. The distribution of similarity scores of the total of 65,541 WIDs is shown in Fig. 6. The average similarity score was 4.26, and the range of similarity scores varied from 0 to 21.
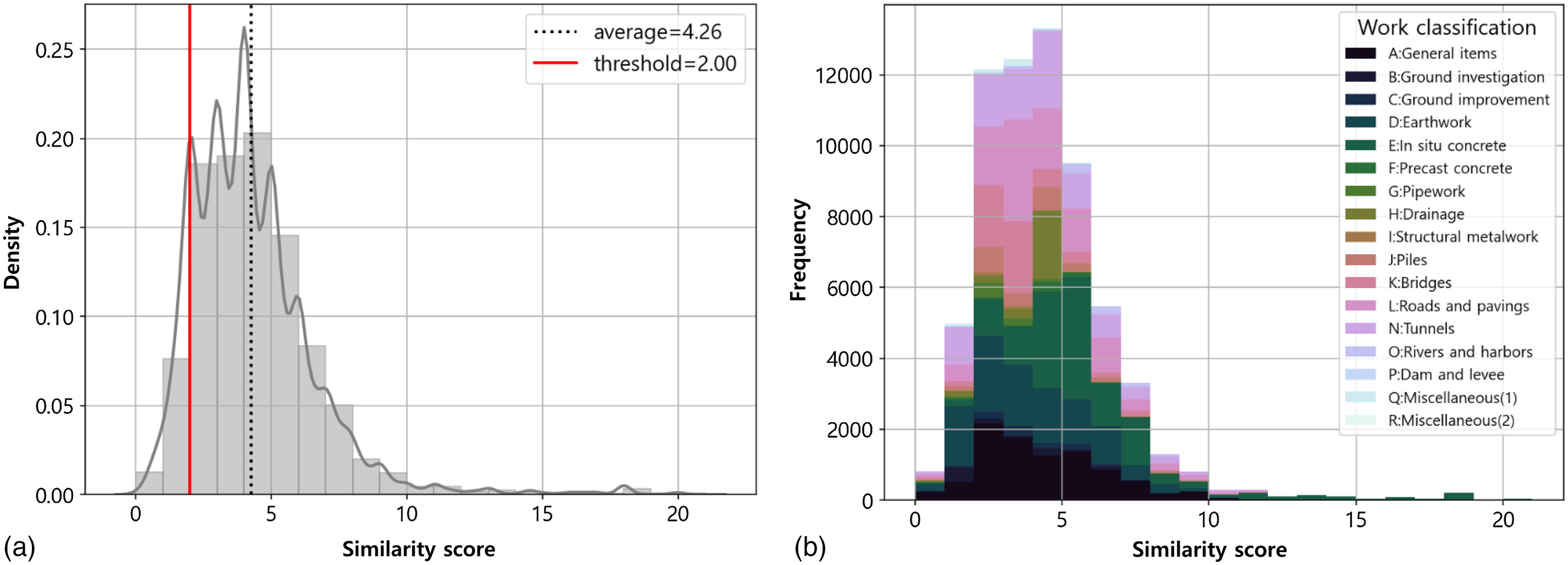
The left-hand side of the graph (a) in Fig. 6 shows the density distribution by the similarity score, and the right-hand side of the graph (b) shows the difference of the similarity score by construction work classification. Most of the similarity scores were concentrated on four points, and the similarity scores differed by each work classification. As shown in Table 3, the average similarity score of the “In situ concrete” classification (i.e., 5.64) was higher than that of other work classifications, in parallel with the number of WIDs. Contrary to the “In situ concrete” classification, the similarity score of the “Dams and levees” classifications was low, and the number of WID data was small. WIDs of frequently used work classifications tend to be prepared similarly to the standard WID in the BOQ more than WIDs in less-used work classifications.
| Work classification (first level) | Count | Mean | Standard deviation | Min. | Median | Max. |
|---|---|---|---|---|---|---|
| Total | 65,541 | 4.26 | 2.30 | 0.00 | 4.00 | 21.00 |
| A: General items | 9,279 | 4.12 | 2.12 | 0.00 | 3.90 | 13.82 |
| B: Ground investigation | 959 | 3.05 | 1.57 | 0.60 | 2.53 | 7.36 |
| C: Ground improvement | 946 | 3.88 | 1.84 | 0.25 | 3.50 | 11.50 |
| D: Earthwork | 10,441 | 3.88 | 2.08 | 0.20 | 3.67 | 15.50 |
| E: In situ concrete | 12,527 | 5.64 | 3.15 | 0.33 | 5.00 | 21.00 |
| F: Precast concrete | 474 | 4.21 | 1.34 | 1.00 | 4.00 | 8.90 |
| G: Pipework | 871 | 3.26 | 2.02 | 0.10 | 2.95 | 13.00 |
| H: Drainage | 2,588 | 3.71 | 0.79 | 0.30 | 4.00 | 9.42 |
| I: Structural metalwork | 211 | 3.00 | 1.38 | 0.33 | 2.71 | 10.17 |
| J: Piles | 2,309 | 3.61 | 1.53 | 0.29 | 3.73 | 9.25 |
| K: Bridges | 5,216 | 3.42 | 1.57 | 0.33 | 3.00 | 12.00 |
| L: Roads and paving | 9,714 | 4.18 | 1.84 | 0.23 | 3.80 | 13.00 |
| N: Tunnels | 8,578 | 4.07 | 1.97 | 0.40 | 4.00 | 16.00 |
| O: Rivers and harbors | 884 | 5.57 | 1.78 | 0.12 | 5.75 | 10.57 |
| P: Dams and levees | 29 | 2.00 | 0.00 | 2.00 | 2.00 | 2.00 |
| Q: Miscellaneous(1) | 434 | 2.88 | 1.06 | 0.71 | 3.00 | 8.17 |
| R: Miscellaneous(2) | 81 | 2.99 | 1.92 | 0.67 | 3.00 | 8.00 |
Although the algorithm assigned the most similar standard WCC to the WIDs, an assigned standard WCC with a low similarity score might not represent the original intent of the WID in the unstandardized BOQ. Thus, to verify the performance of the proposed algorithm, the authors manually examined setting the threshold that distinguishes between correctly assigned and unassigned. In most instances, similarity scores of 2 or higher were correctly classified, and results with scores of less than 2 were shown as incompletely assigned. The correctly assigned results that exceeded the threshold were 91.12%; the authors set the accuracy of automatically assigning the standard WCC.
In Table 4, WIDs correctly assigned high similarity scores are organized as an example. A result with a high similarity score has very similar constituent words. WIDs assigned the same standard WCC are classified as the same work item and stored in the same database.
| No. | Detailed WID from unstandardized BOQ | Standard WID | Similarity score | Standard WCC |
|---|---|---|---|---|
| 1 | [“earthwork”, “clearing and grubbing”, “and”, “logging”, “logging”, “under”] | [“earthwork”, “clearing and grubbing”, “logging”, “under”, “logging”, “under”] | 10.67 | CDA210 |
| 2 | [“earthwork”, “clearing and grubbing”, “and”, “logging”, “logging”, “over”] | [“earthwork”, “clearing and grubbing”, “over”, “logging”, “over”] | 10.67 | CDA230 |
| 3 | [“tunnel”, “lining”, “concrete”, “lining”, “expansion joint”] | [“tunnel work”, “in-situ concrete”, “concrete”, “lining”, “expansion joint”, “expansion joint”, “lining concrete”] | 9.75 | CNE510 |
| 4 | [“structural work”, “B”, “Bongsang 3 bridge”, “PSC Beam bridge”, “L300M”, “PSC”, “BEAM”, “manufacturing”, “and”, “installation”, “PSC”, “BEAM”, “manufacturing”, “L30m”] | [“precast”, “concrete work”, “post-tensioned beam”, “PSC beam”, “manufacturing”, “PSC beam”, “manufacturing”, “PSC beam”, “manufacturing”] | 8.9 | CFB601 |
| 5 | [“drainage”, “reinforced retaining wall”, “reinforced retaining wall”, “reinforced soil”, “building”, “and”, “compaction”] | [“ground improvement work”, “specific retaining wall”, “reinforced soil”, “retaining wall”, “block”, “reinforced soil”, “building”, “and” “compaction”] | 8.6 | CCG110 |
| 6 | [“drainage”, “temporary”, “earth anchor”, “equipment”, “assembling”, “and”, “dissolution”] | [“general work”, “etc.”, “temporary bracing”, “earth anchor”, “earth anchor”, “equipment assembling, “and”, “dissolution”] | 8.5 | CAE250 |
| 7 | [“paving”, “asphalt”, “base”, “asphalt”, “base”, “T10cm”] | [“road”, “and”, “paving”, “asphalt”, “paving”, “base”, “base”, “base paving and compaction”, “asphalt paving T10 centimeter”] | 8.42 | CLC300 |
In Table 5, WIDs assigned low similarity scores are examined. The results show that the detailed WIDs from the unstandardized BOQ and assigned standard WIDs were not correctly matched, and the composing words were inconsistent. In several cases, there is no appropriate WCC to be assigned to represent the WID. For example, the detailed WID with the lowest similarity score (i.e., 0.25) in the first row of Table 5 represented the “provisional sum.” But this item is unnecessary for the work item description and should not be included in the WID in BOQ, and there should be no appropriate WCC that can represent the item. In addition, texts such as “material price” and “coarse aggregate” appear repeatedly in Table 5, indicating government-provided materials in Korea. The Korean government directly supplies some primary construction materials, such as cement, rebar, aggregate, ready-mixed concrete, and fume tubes, to secure a stable supply. Thus, such work items do not have proper WCCs to be allocated because they are not included in BOQ estimates. Accordingly, the authors found that results with low similarity were sometimes due to the absence of a standard WCC for WIDs. The standard code management system should complement such a standard classification code for proper cost estimation in the future.
| No. | Detailed WID from unstandardized BOQ | Standard WID | Similarity score | Standard WCC |
|---|---|---|---|---|
| 1 | [“provisional sum”] | [“ground improvement”, “diaphragm wall”, “section”, “except”, “material”, “depth”, “under”, “except artificial hardener”, “under 5m depth”] | 0.25 | CCE310 |
| 2 | [“earthwork”, “material price”, “coarse aggregate”, “40mm”, “include loading fee”] | [“earthwork”, “clearing and grubbing”,” uprooting”, “uprooting”, “clearing and grubbing”] | 0.67 | CDA100 |
| 3 | [“slope protection”, “material price”, “coarse aggregate”] | [“earthwork”, “soil cutting”, “road”, “fill lot”, “slope”, “grading”, “fill lot”, “slope”, “grading”] | 1 | CDG150 |
| 4 | [“drainage”, “culverting”, “swellable water stop”] | [“tunnel”, “waterproof”, “and”, “drainage”, “drainage facility”, “tunnel drainage polyvinyl”] | 1 | CNI270 |
| 5 | [“drainage”, “culverting”, “back filing”, “back filing”, “sub-base SB1 excluding material”] | [“tunnel”, “waterproof”, “and”, “drainage”, “drainage facility”, “tunnel drainage polyvinyl”] | 1 | CNI270 |
| 6 | [“drainage”, “culverting”, “back filing”, “back filing”, “roadbed filled up ground compaction”] | [“ground improvement”, “weak ground treatment”, “compaction”, “compaction”, “subsidence soil filling and compacting”] | 1 | CCD300 |
| 7 | [“earthwork”, “material price”, “coarse aggregate”, “40mm”, “include loading fee”] | [“tunnel”, “waterproof”, “and”, “drainage”, “drainage facility”, “tunnel drainage polyvinyl”] | 1 | CNI270 |
Table 6 shows controversial results that looked correctly assigned but had a low similarity. The WID in the first row of Table 6 represented “a weak ground treatment work” and was assigned to a standard WCC representing “CCD110.” The “CCD100” class means “weak ground treatment,” but it also means “excavation and replacement.” The “CCD120” class means “weak ground treatment,” but it also means “compulsory replacement.” It seems impossible to clearly distinguish whether the WID is “CCD100” or “CCD120.” This example shows that some WIDs of the BOQ have insufficient information to select the appropriate WCCs. The work to supplement the insufficient information in the WID could be performed in future studies.
| No. | Detailed WID from unstandardized BOQ | Standard WID | Similarity score | Standard WCC |
|---|---|---|---|---|
| 1 | [“earthwork”, “weak ground treatment”, “GCP”, “700mm”] | [“ground improvement”, “weak ground treatment”, “replacement”, “excavation and replacement”, “excavation and replacement”] | 0.86 | CCD110 |
| 2 | [“drainage”, “culvert”, “styrofoam”, “styrofoam”, “T5mm”] | [“road”, “and”, “paving”, “concrete”, “paving joint”, “styrofoam joint”, “styrofoam joint”, “styrofoam joint”, “T5millimeter”] | 1.33 | CLE400 |
| 3 | [“drainage”, “culvert”, “plate bearing test”, “T5mm”] | [“pile work”, “pile load test”, “static”, “loading”, test”, “static”, “loading”, “test”, “static loading test”] | 1.33 | CJI100 |
Review of Assigned Standard WCC by Projects
The framework allows not only automatic assignment of the standard WCC to WID in unstandardized BOQs but also the collection of the unit cost data attached in the BOQ. Unit cost collection has the potential to help comparison and verification of construction project cost. The authors selected five projects in 2019 to investigate the characteristics of the assigned data grouped in the same standard WCC. All five projects were general road construction projects, but the entire construction cost varied depending on the length and width of the road and the number of bridges and tunnels included. Table 7 shows the project information and automatic assigning results of the five BOQs. The number of correctly assigned WIDs means the assignment results had a similarity score of two or higher. The average accuracy for the five projects was 87.48%.
| Category | Project information | Results | |||||||
|---|---|---|---|---|---|---|---|---|---|
| Length (km) | Number of lanes | Number of bridges | Number of tunnels | Construction cost (KRW) | Number of WIDs | Number correctly assigned WIDs | Number of assigned WCC | Accuracy | |
| Project 1 | 5.1 | 2 | 2 | 2 | 56,692,255,493 | 1,326 | 1,220 | 213 | 92.00% |
| Project 2 | 5.1 | 4–6 | 7 | 0 | 43,115,438,596 | 2,059 | 1,803 | 197 | 87.60% |
| Project 3 | 9.7 | 2 | 5 | 1 | 25,925,156,509 | 952 | 767 | 156 | 80.60% |
| Project 4 | 13.2 | 2 | 7 | 0 | 35,402,567,337 | 1,458 | 1,298 | 205 | 89.00% |
| Project 5 | 12.0 | 2 | 8 | 1 | 49,035,238,567 | 831 | 733 | 183 | 88.20% |
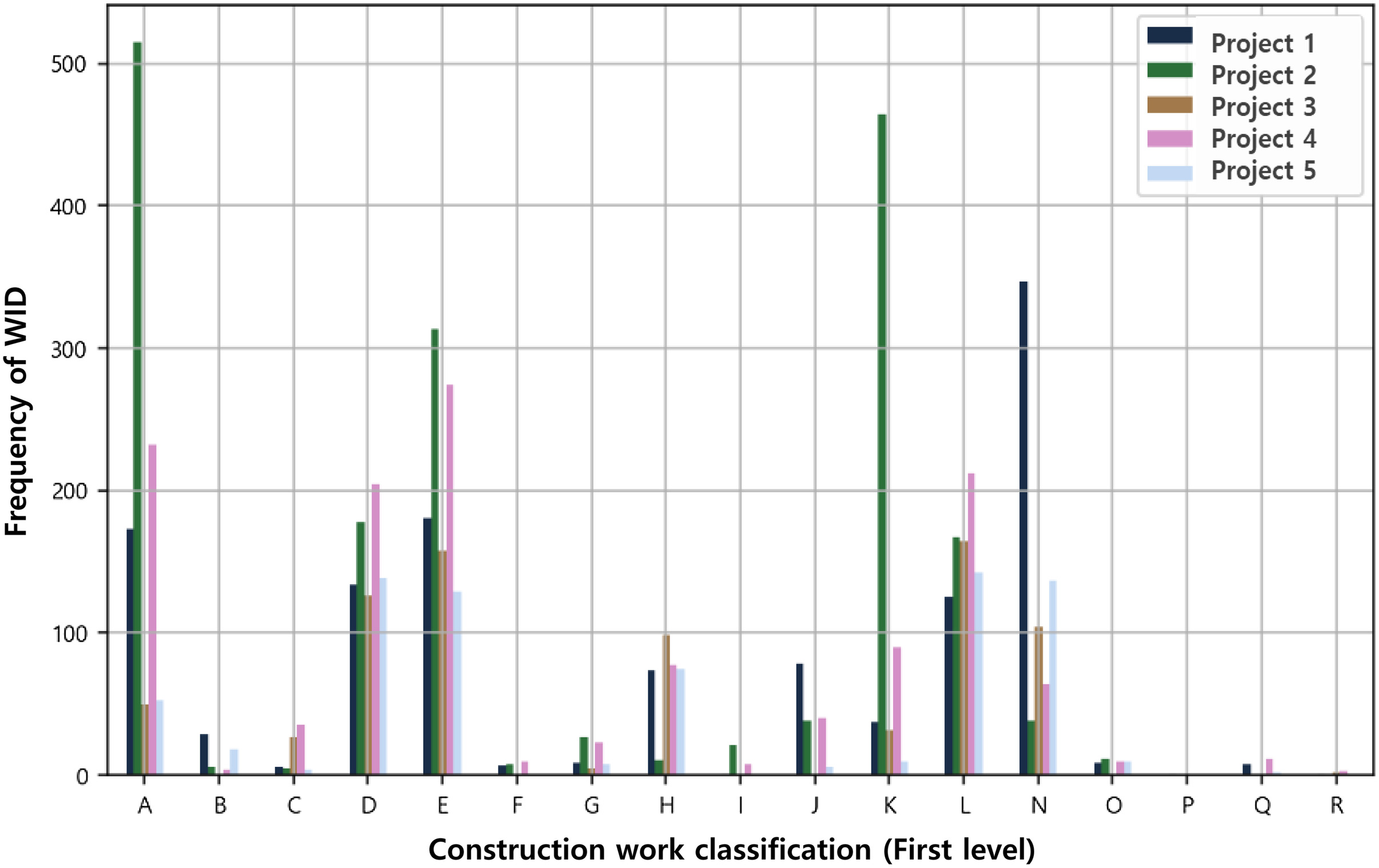
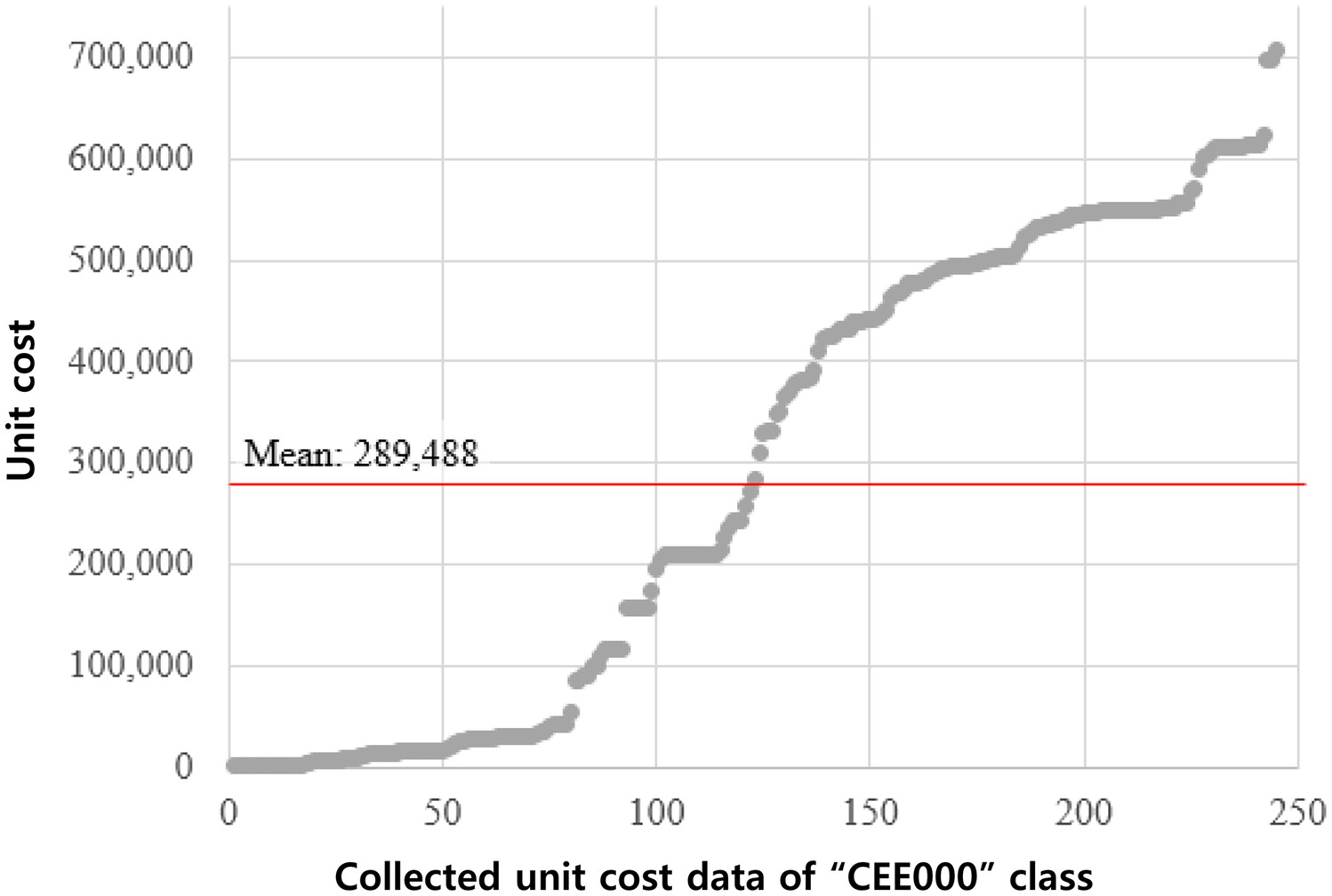
Table 8 shows a large difference in the number of data according to the construction classification, and there are also construction work classifications that are not used in the roadway construction BOQ. Fig. 7 is plotted to see the difference in the number of WIDs by construction work classification according to the project. The notable point is that in the case of Project 2, many WIDs were classified in classes “A: General items” and “K: Bridges.” From the results, the authors inferred that the measurement method and usage of standard work item description vary depending on the characteristics of the project or the propensity of the estimator. Also, in the current situation, the collected unit cost data using standard WCC as an index is difficult to consider as a reliable cost representing the standard WCC. This is because the difference in the amount of data for each standard WCC is large, and the number of collected unit costs is very small. Among the five projects selected in 2019, the most frequently used standard WCC was “CEE000,” accounting for 246 data out of 5,821 total WIDs. The 246 WIDs were the results after excluding the unit cost data entered in zero or negative values and also excluding the unproperly assigned result, even when the similarity score was higher than the threshold. The distribution of the unit cost is plotted in Fig. 8. The 246 unit cost data became the database of “CEE000” WCC. The standard WCC indicates “stiffener and rebar work during reinforced concrete work.” The median value of the unit cost data is 289,488 Korean won, but the unit cost ranges from almost zero to 700,000 Korean won or more. It means the cause of the difference in unit cost can be found depending on the characteristics of each project and the work (e.g., tunnel or bridge). When the unit cost data are continuously collected, they can be used to derive a more appropriate construction cost estimation.
| Construction work classification (first level) | Project 1 | Project 2 | Project 3 | Project 4 | Project 5 | |||||
|---|---|---|---|---|---|---|---|---|---|---|
| Freq. | Average similarity | Freq. | Average similarity | Freq. | Average similarity | Freq. | Average similarity | Freq. | Average similarity | |
| A: General items | 173 | 4.62 | 515 | 4.36 | 50 | 3.60 | 232 | 5.12 | 53 | 4.77 |
| B: Ground investigation | 29 | 4.75 | 6 | 2.17 | 0 | 0 | 4 | 3.10 | 18 | 4.61 |
| C: Ground improvement | 6 | 2.86 | 5 | 3.45 | 27 | 3.44 | 35 | 4.78 | 4 | 3.97 |
| D: Earthwork | 134 | 4.90 | 178 | 4.44 | 126 | 3.41 | 204 | 4.34 | 139 | 3.89 |
| E: In situ concrete | 181 | 6.51 | 313 | 6.35 | 158 | 3.92 | 274 | 6.83 | 129 | 6.37 |
| F: Precast concrete | 7 | 3.71 | 8 | 3.75 | 0 | 0 | 10 | 4.15 | 0 | 0 |
| G: Pipework | 9 | 3.07 | 27 | 4.56 | 5 | 2.50 | 23 | 3.66 | 8 | 2.54 |
| H: Drainage | 74 | 3.97 | 11 | 3.87 | 98 | 3.97 | 77 | 3.82 | 75 | 3.84 |
| I: Structural metalwork | 1 | 2.00 | 21 | 3.28 | 0 | 0 | 8 | 5.19 | 0 | 0 |
| J: Piles | 78 | 3.87 | 38 | 4.69 | 1 | 6.40 | 40 | 4.87 | 6 | 6.13 |
| K: Bridges | 37 | 2.69 | 464 | 3.06 | 32 | 2.75 | 90 | 3.17 | 10 | 2.45 |
| L: Roads and paving | 125 | 4.15 | 167 | 3.86 | 164 | 3.59 | 212 | 4.81 | 142 | 4.89 |
| N: Tunnels | 347 | 4.95 | 38 | 4.37 | 104 | 3.98 | 64 | 5.35 | 137 | 4.40 |
| O: Rivers and harbors | 9 | 6.86 | 12 | 4.90 | 0 | 0 | 10 | 4.03 | 10 | 4.67 |
| P: Dams and levees | 1 | 2.00 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| Q: Miscellaneous (1) | 8 | 3.77 | 0 | 0 | 0 | 0 | 12 | 2.67 | 2 | 3.50 |
| R: Miscellaneous (2) | 1 | 3.00 | 0 | 0 | 2 | 3.33 | 3 | 4.33 | 0 | 0 |
| Total/average | 1,220 | 3.98 | 1,803 | 4.08 | 767 | 2.41 | 1,298 | 4.13 | 733 | 3.30 |
Limitations of the Standardization Process
The authors proposed the rule-based WID matching algorithm to standardize the BOQ. The concept of the algorithm involved focusing on the inclusion of words in the WID. This can help standardize detailed BOQ work by efficiently finding the most similar standard WID. However, there are some limitations.
First, the limitation in the algorithmic aspect is as follows: because only word inclusion is mainly considered, the entire length of the WID and the importance of the primary keyword cannot be considered when scoring the similarity. Second, in terms of data verification, the ultimate goal is to derive an appropriate unit price by collecting unit price data for each WID. However, there is a limit to deriving the optimal unit price for each WID using only the data collected in this paper. Because the characteristics of the project are diverse, it will be possible to extract an appropriate unit price when more data are collected in a standardized format.
Conclusions
Despite the importance of standardized data acquisition from the initial stage of a construction project, it is difficult in practice for quantity surveyors and estimators to prepare the standardized BOQ. Not only will an inexperienced estimator be unable to recognize and memorize all the construction work classification code systems, but matching an appropriate standard WCC to a WID in a BOQ is also a time-consuming and challenging process. Therefore, this research proposed a framework that automatically assigns the most proper standard WCC to the detailed WID in the BOQ. Forty-four roadway construction BOQs were prepared for the experiment; the authors devised two essential processes for automatic assignment. First, a method was designed to convert the short WIDs in the original unstandardized BOQ into a string containing more features. In other words, the authors performed the task of inheriting the upper-class work names to the previously short WIDs to increase the amount of information for string matching. Second, a similarity scoring algorithm was suggested to match the most similar string between standard WIDs with WCCs and detailed WIDs from the original unstandardized BOQ. In conclusion, 91.12% of WIDs from the unstandardized BOQ could be standardized, and unit cost data were collected through this series of processes.
The contributions of this paper are summarized as follows. First, the proposed framework is expected to improve the process of matching the standard WCC when preparing BOQs in the procurement stage. Thanks to this process, quantity surveyors or estimators can reduce the effort taken to assign the correct standard work classification code in preparing the BOQ. Second, this paper suggests the possibility of an automatic collection of unit costs from the early stage of the construction project using the BOQ because the standardized work item description can clarify the cost and check the reliability of the data. Finally, the algorithm for similarity matching can be applied at another construction stage. For example, when creating multiple BOQs in the construction phase for design changes or interim settlements, this algorithm can be used to consolidate them.
Even with the proposed framework for the standardization of the BOQ, further studies should be conducted to improve the standardization performance of the BOQ and verify the estimated construction unit cost. The authors found that standard work classification codes had some imperfections in covering all WIDs of a BOQ. Also, some work item descriptions of standard work classification codes were subject to ambiguity that could confuse practitioners. The limitations of the standard WCC itself could be supplemented by adding a new standard classification code while continuously collecting WIDs of standardized BOQs.
Also, until this research, the unit cost collected using the proposed algorithm varied greatly and made it hard to define the representative unit cost of each WID. However, within the next few steps, the authors expect it to be possible to estimate reliable project cost using the collected unit cost database from the BOQ. In addition, the standardized WIDs and unit cost data generated during the procurement stage should be linked to the next phase of construction to monitor how the unit cost changes. Until now, the BOQ was not standardized and thus could not be used in later stages; however, the automatic code assignment framework proposed in this study will open up the possibility of this. That helps to review the continuity of construction cost data throughout its entire life cycle. Furthermore, the proposed process of the automatic assignment of standard WCCs to WIDs in BOQs could be applied in other countries, such as Malaysia, Australia, or other countries that use the BOQ format for the procurement and contract process.
Data Availability Statement
Except for the data, models, and code provided externally, the analytical data and results for this study are available from the corresponding author on request.
Acknowledgments
This research was supported by a Korea Agency for Infrastructure Technology Advancement (KAIA) grant funded by the Ministry of Land, Infrastructure, and Transport (National Research for Smart Construction Technology: Grant 22SMIP-A158708-03) and by the BK21 PLUS research program of the National Research Foundation of Korea. The authors sincerely acknowledge the data support from Public Procurement Service in Korea and IDEA Information Technology.
References
Akbar, A. R. N., M. F. Mohammad, M. Maisyam, and E. W. W. Hong. 2015. “Desirable characteristics of Malaysian standard method of measurements (MySMMs) in meeting industry quality standards.” Procedia-Social Behav. Sci. 202 (Aug): 76–88. https://doi.org/10.1016/j.sbspro.2015.08.210.
Al Qady, M., and A. Kandil. 2015. “Automatic classification of project documents on the basis of text content.” J. Comput. Civ. Eng. 29 (3): 04014043. https://doi.org/10.1061/(ASCE)CP.1943-5487.0000338.
Bandi, S., F. Abdullah, and R. Amiruddin. 2014. “Recapitulating the issues concerning the applications of the bills of quantities.” Int. J. Built Environ. Sustainability 1 (1): 63–70. https://doi.org/10.11113/ijbes.v1.n1.10.
Barnes, M. 1992. “Introduction.” In CESMM3 handbook, 1–5. London: Thomas Telford Publishing.
Barnes, M., and M. Attridge. 2019. “Preparation of the bill of quantities.” In CESMM4 revised: Handbook, 23–39. London: ICE Publishing.
Caldas, C. H., and L. Soibelman. 2003. “Automating hierarchical document classification for construction management information systems.” Autom. Constr. 12 (4): 395–406. https://doi.org/10.1016/S0926-5805(03)00004-9.
Cerezo-Narváez, A., A. Pastor-Fernández, M. Otero-Mateo, and P. Ballesteros-Pérez. 2020. “Integration of cost and work breakdown structures in the management of construction projects.” Appl. Sci. (Switzerland) 10 (4): 1386. https://doi.org/10.3390/app10041386.
Cho, D., J. S. Russell, and J. Choi. 2013. “Database framework for cost, schedule, and performance data integration.” J. Comput. Civ. Eng. 27 (6): 719–731. https://doi.org/10.1061/(ASCE)CP.1943-5487.0000241.
Cohen, W. W., P. Ravikumar, and S. E. Fienberg. 2003. “A comparison of string distance metrics for name-matching tasks.” In Proc., IJCAI-2003 Workshop on Information Integration on the Web (IIWeb-03). Mountain View, CA: Research Institute for Advanced Computer Science.
Cunningham, T. 2014. The work and skills base of the quantity surveyor in Ireland—An introduction. Dublin, Ireland: Technological Univ. Dublin. https://doi.org/10.21427/prwx-z232.
Ekholm, A. 1996. “A conceptual framework for classification of construction works.” Electron. J. Inf. Technol. Constr. 1 (Nov): 25–50.
Gomma, W. H., and A. A. Fahmy. 2013. “A survey of text similarity approaches.” Int. J. Comput. Appl. 68 (13): 13–18. https://doi.org/10.5120/11638-7118.
Hua, W., Z. Wang, H. Wang, K. Zheng, and X. Zhou. 2015. “Short text understanding through lexical-semantic analysis.” In Proc., 2015 IEEE 31st Int. Conf. on Data Engineering, 495–506. New York: IEEE. https://doi.org/10.1109/ICDE.2015.7113309.
Islam, A., and D. Inkpen. 2008. “Semantic text similarity using corpus-based word similarity and string similarity.” ACM Trans. Knowl. Discovery Data 2 (2): 1–25. https://doi.org/10.1145/1376815.1376819.
Jalam, A. A., N. Gambo, A. Dahiru, and A. A. Aliyu. 2018. “Assessing the severity of errors in bills of quantities for public building projects in Nigeria’s construction industry.” Galore Int. J. Appl. Sci. Humanities 2 (2): 25–35.
Jeong, S. 2020. “Comparing string similarity algorithms for recognizing task names found in construction documents.” Korean J. Constr. Eng. Manage. 21 (6): 125–134.
Jung, Y., and G. E. Gibson. 1999. “Planning for computer integrated construction.” J. Comput. Civ. Eng. 13 (4): 217–225. https://doi.org/10.1061/(ASCE)0887-3801(1999)13:4(217).
Juszczyk, M., R. Kozik, A. Leśniak, E. Plebankiewicz, and K. Zima. 2014. “Errors in the preparation of design documentation in public procurement in Poland.” Procedia Eng. 85 (Jan): 283–292. https://doi.org/10.1016/j.proeng.2014.10.553.
Kang, L. S., and B. C. Paulson. 1997. “Adaptability of information classification systems for civil works.” J. Constr. Eng. Manage. 123 (4): 419–426. https://doi.org/10.1061/(ASCE)0733-9364(1997)123:4(419).
Kenter, T., and M. de Rijke. 2015. “Short text similarity with word embeddings.” In Proc., 24th ACM Int. on Conf. on Information and Knowledge Management, 1411–1420. New York: Association for Computing Machinery.
Kesavaraj, G., and S. Sukumaran. 2013. “A study on classification techniques in data mining.” In Proc., 4th Int. Conf. on Computing, Communications and Networking Technologies, ICCCNT 2013, 2–8. New York: IEEE.
Le, Y., J. S. Ren, Y. Ning, Q. H. He, and Y. Li. 2009. “Life cycle cost integrative management in construction engineering.” In Proc., 1st Int. Conf. on Information Science and Engineering, ICISE 2009, 4367–4370. New York: IEEE.
Liddy, E. D. 2001. “Natural language processing.” In Encyclopedia of library and information science. 2nd ed. New York: Marcel Decker.
Martínez-Rojas, M., N. Marín, and M. A. V. Miranda. 2016. “An intelligent system for the acquisition and management of information from bill of quantities in building projects.” Expert Syst. Appl. 63 (Nov): 284–294. https://doi.org/10.1016/j.eswa.2016.07.011.
Martínez-Rojas, M., N. Marín, and M. A. Vila. 2015. “An approach for the automatic classification of work descriptions in construction projects.” Comput.-Aided Civ. Infrastruct. Eng. 30 (12): 919–934. https://doi.org/10.1111/mice.12179.
Martínez-Rojas, M., J. M. Soto-Hidalgo, N. Marín, and M. A. Vila. 2018. “Using classification techniques for assigning work descriptions to task groups on the basis of construction vocabulary.” Comput.-Aided Civ. Infrastruct. Eng. 33 (11): 966–981. https://doi.org/10.1111/mice.12382.
Mo, Y., D. Zhao, J. Du, M. Syal, A. Aziz, and H. Li. 2020. “Automated staff assignment for building maintenance using natural language processing.” Autom. Constr. 113 (May): 103150. https://doi.org/10.1016/j.autcon.2020.103150.
Moon, S., G. Lee, and S. Chi. 2021. “Semantic text-pairing for relevant provision identification in construction specification reviews.” Autom. Constr. 128 (Aug): 103780. https://doi.org/10.1016/j.autcon.2021.103780.
Ndekugri, I. E., and R. McCaffer. 1988. “Management information flow in construction companies.” Construct. Manage. Econ. 6 (4): 273–294. https://doi.org/10.1080/01446198800000024.
Park, E., and S. Cho. 2014. “KoNLPy: Korean natural language processing in Python.” In Proc., 26 th Annual Conf. on Human and Language Technology, 133–136. Seoul: Korean Institute of Information Scientists and Engineers.
Powell, G. 2012. Construction contract preparation and management: From concept to completion. Basingstoke, UK: Palgrave Macmillan.
PPCS (Public Construction Cost estimation System). 2021. “Public procurement cost system in Korea.” Accessed July 16, 2021. https://pccs.g2b.go.kr:8784/c3r/index.do.
Rashid, R., M. Mustapa, and S. N. A. Wahid. 2006. “Bills of quantities—Are they still useful and relevant today?” In Vol. 21 of Proc., Int. Conf. on Construction Industry, 1–10. Padang, Indonesia: Universiti Teknologi Malaysia Institutional Repository.
Razali, A., A. Tajudin, A. Fadzli, and A. Tajuddin. 2014. “Applicability bill of quantities in construction procurement.” Int. J. Eng. Sci. Invent. 3 (4): 31–34.
Ristad, E. S., and P. N. Yianilos. 1998. “Learning string-edit distance.” IEEE Trans. Pattern Anal. Mach. Intell. 20 (5): 522–532. https://doi.org/10.1109/34.682181.
Seeley, I. H. 1993. “General arrangement and contents of civil engineering bills of quantities.” In Civil engineering quantities, Macmillan building and surveying series, 42–58. London: Palgrave.
Senaratne, S., and M. Rodrigo. 2019. “Teaching building measurement principles to suit the transforming construction industry.” In Proc., 43rd Australasian Universities Building Education Association (AUBEA) Conf.: Built to Thrive: Creating Buildings and Cities that Support Individual Well-being and Community Prosperity, 361–369. Noosa, QLD, Australia: CQ Univ.
Sequeira, S., and E. Lopes. 2015. “Simple method proposal for cost estimation from work breakdown structure.” Procedia Comput. Sci. 64 (Jan): 537–544. https://doi.org/10.1016/j.procs.2015.08.559.
Uysal, A. K., and S. Gunal. 2014. “The impact of preprocessing on text classification.” Inf. Process. Manage. 50 (1): 104–112. https://doi.org/10.1016/j.ipm.2013.08.006.
Wang, R., D. Zhong, Y. Zhang, J. Yu, and M. Li. 2015. “A multidimensional information model for managing construction information.” J. Ind. Manage. Optim. 11 (4): 1285. https://doi.org/10.3934/jimo.2015.11.1285.
Webster, J. J., and C. Kit. 1992. “Tokenization as the initial phase in NLP.” In Proc., 14th Conf. on Computational Linguistics, 1106. Morristown, NJ: Association for Computational Linguistics.
Yun, S.-H. 2010. “A study on the standardized cost code system for BoQ for efficiency of cost management in public construction projects.” J. Archit. Inst. Korea 26 (12): 167–174.
Information & Authors
Information
Published In

Journal of Construction Engineering and Management
Volume 149 • Issue 2 • February 2023
Copyright
This work is made available under the terms of the Creative Commons Attribution 4.0 International license, https://creativecommons.org/licenses/by/4.0/.
History
Received: May 25, 2022
Accepted: Sep 6, 2022
Published online: Nov 21, 2022
Published in print: Feb 1, 2023
Discussion open until: Apr 21, 2023
Authors
Metrics & Citations
Metrics
Citations
Download citation
If you have the appropriate software installed, you can download article citation data to the citation manager of your choice. Simply select your manager software from the list below and click Download.
Cited by
- Ravindu Kahandawa, Niluka Domingo, Gregory Chawynski, S. R. Uma, Methods to Include the Impact of Factors in Postearthquake Cost Estimations for Earthquake Damage Repair Work, Natural Hazards Review, 10.1061/NHREFO.NHENG-1700, 25, 1, (2024).